Introdução
Tempo estimado de leitura: 1min
Chegará o momento que como um profissional da área de tecnologia, um desesvolvedor, vai precisar utilizar todos os seus conhecimentos da área para poder planejar e executar um desenvolvimento de uma aplicação, seja ela mobile, web ou desktop, ou vai precisar trabalhar com o desenvolvimento de um produto que já existe...
A principal intenção desse trabalho é conseguir deixar claro quais passos tomar para o desenvolvimento de um trabalho de mundo real. Desde o design do produto até a sua conclusão devemos encarar alguns passos como a prototipação, levantamento de requisitos, para poder fazer uma priorização de cada funcionalidade, configuração de ambiente, documentação, integração... A lista é vasta mas a ideia é que esse "guia" mostra o caminho das pedras para poder prosseguir.

Sofisticação Técnica - Como se virar
Tempo estimado de leitura: 1min
Bem, assim como tudo na vida, a prática leva a perfeição, sabe-se que quando conhecemos ferramentas novas, alguns estilos e técnicas passamos a inserir isso no nosso cotidiano e trazemos a praticidade vindo da experiência e de alguns costumes.
Bem a ideia desse capítulo é passar um conjunto de técnicas ou formas de enfrentar um problema sozinho, antes de recorrer a forças maiores, como aquele seu amigo que entende bem mais do assunto.
Aqui iremos falar sobre:
Como Googlar
Tempo estimado de leitura: 4min
Contexto
Bem nos encontramos no mundo da informação e sabemos que basicamente qualquer resposta está ao alcance dos nossos dedos, basta apenas termos acesso a internet e fazermos uma rápida pesquisa em uma ferramenta voltada para busca em acervos web.
Nesse ponto temos uma certa variedades de ferramentas que nos auxiliam a encontrar o que precisamos, o Bing, Yahoo!, DuckDuck Go, e alguns outros que de vez em quando esbarramos em algum computador. Embora tenhamos uma variedade ampla de buscadores, não dá para não associar a supremacia da Google nesse aspecto, por dominar cerca de 94% de todo tráfego orgânico da surface (parte 'superficial' que possui indexadores para serem localixados) internet.
E você precisa encontrar a solução de um problema ou uma definição precisa a cerca de um assunto, as necessidades podem ser diversas, mas a chances de encontrar isso são altíssimas. Então por conta disso voltamos ao google.
Conseguindo Melhores Resultados na Busca
Bem infelizmente quando vamos atrás de alguma informação na internet, podemos enfrentar alguns problemas, por conta da língua, ou da grande quantidade de informações e definições similares para alguns nichos diferentes.
Um exemplo simples: você pode estar procurando por alguma coisa relacionada a Harry Potter no google e usar apenas Hp, e se depara com informações a cerca de impressoras e suporte.
Por conta desse e alguns outros pequenos problemas (como língua e ambiguidades), é necessário conhecer algumas "técnicas" para conseguir resultados eficientes que melhorem o nosso resultado de busca.
1: Palavras chave:
É possível encontrar o que procura bem rápido usando várias palavras chave na sua pesquisa, ao invés de apenas uma palavra ou termo.
Ao procurar por: Vídeos de crianças engraçadas procure por cada palavra separadamente ao invés da frase completa. Então o ideal nesse cenário seria usar apenas Crianças engraçadas e usar o filtro de busca dentro da ferramenta.
Evite algo como: quero ver vídeos de crianças engraçadas por exemplo. Isso mais atrapalha do que ajuda a busca.
2: Use aspas:
Caso se recorde de uma frase ou termo completo que tenha interesse em achar, coloque a frase exata entre aspas, dessa forma o google irá buscar a string exata que escreveu ao invés de tentar filtrar por outros aspectos para encontrar "relacionados" ou "conceitos" que são parecidos.
Eperimente por exemplo pesquisar um nome completo entre aspas, as chances de encontrar a pessoa específica é bem maior do que apenas usar o nome completo na busca. Dessa forma você evita que o google procure por pessoas com cada um dos nomes e que ele faça algumas combinações com a ordem para tentar achar o que você procura.
3: Use o menos, como operador de exclusão
Caso por exemplo queira saber algo sobre Washington entretanto não quer saber de Washington DC, coloque o - (menos) antes, da palavra DC.
Washington -DC (o menos deve estar antes, e colado ao termo que não quer na sua busca).
Uma boa é usar as aspas para excluir uma frase inteira colocando o
-logo antes a frase (entre aspas).
4: Use o OU
O google permite que você faça busca de duas coisas ao mesmo tempo com esse operador. Experimente pesquisar jogos de nintendo OU jogos de playstation, ele retornará parte da busca voltada para cada um.
5: Operador .. (Ponto Ponto)
Funciona para casos em que queira colocar um filtro de intervalo numérico, caso queira buscar músicas de 1980 até 2000, pode pesquisar como:
Músicas 1980..2000
6: Operador Site:
Caso saiba que um conteúdo vai ser encontrado dentro de um site específico, pode evitar gerar mais sugestões de lugares desnecessários colocando site:Fonte.com ao final da busca.
Via Lactea site:Nasa.gov
7: Operador Defina:
Caso não saiba o que uma palavra ou termo significa, use o google como dicionário e coloque Defina: antes do termo que gostaria de pesquisar.
8: Curinga *
O asterisco ao final de uma frase ou termo pede para o google encontrar o termo que completaria aquela sentença como por exemplo:
garota de *, retornará Garota de Ipanema por exemplo. Dessa forma ajuda a gente a se lembrar de algumas coisas.
9: Operador FILETYPE:
Depois de escrever o termo que gostaria de pesquisar, use o FILETYPE: para poder logo em seguida dizer ao google quais são os tipos de arquivos que gostaria que fossem retornados, por exemplo, ao invés de achar algum texto pode optar por retornar uma versão de áudio daquela obra adicionando o FILETYPE:mp3.
10: Utiliza os filtros:
Dentro do Google possui algumas ferramentas de busca, pode filtrar para retornar vídeos, imagens, numa língua específica. Pense que dado momento pode pesquisar por Star Wars, essa busca vai retornar resultados no idioma em que pesquisou, mas se for nos filtros do google vai encontrar uma parte voltada para selecionar o idioma de preferência para retornar aquela informação.
Começando com Linux
Tempo estimado de leitura: 1min
Vamos iniciar a sua experiência com o que possivelmente vai ser o seu sistema operacional mais utilizado. Assim como os demais capítulos desse ebook, existe muito a ser abordado. Nesse capítulo, discutiremos sobre:
Resumão Linux
Tempo estimado de leitura: 2min
Nesse capítulo você terá um 'Resumão' sobre introdução e conceitos básicos e alguns comandos em um terminal Linux, além de aprender como instalar um outro sistema operacional no seu computador ou usar uma ferramenta para poder utilizar algumas outras funções Linux.
Explicação
Criado em 1991 por Linus Torvalds.
Baseado em Unix
O Linux é o Kernel ou Núcleo do Sistema Operacional (faz a comunicação entre o hardware e o sistema operacional)
É desenvolvido por diversas pessoas e empresas ao redor do mundo (vários sistemas operacionais e Kernels baseados no Linux)
Multitarefa / Multiusuário
Distribuições
O que é uma "distro"? Uma distro é uma distribuição baseada no Kernel Linux.
O Linux pode ser "distribuído" por empresas, organizações ou mesmo pessoas, quem podem colocar características próprias no sistema operacional, como configurações, aplicações, sistemas de instalação entre outras peculiaridades, assim damos o nome de distribuição, sua escolha é pessoal e depende da aplicação.
Distribuições mais conhecidas:
- Ubuntu
- Debian
- SuSE
- fedora
- popOS!
Requisitos para Instalação
Processador dual core de 2GHz ou superior.
2 GB de memória RAM.
40 GB de espaço livre no disco rígido.
Dual Boot
Particionar o HD para receber o novo sistema operacional. Bootar um pendrive para colocar o instalador do sistema operacional dentro dele. Dentro da Bios, e com o pendrive no computador fazer ele bootar primeiro o pendrive para rodar o instalador do sistema operacional.
Terminal
O Terminal, Shell ou Konsole é uma linha de comando onde podemos executar programas específicos do Linux.
A maioria dos comandos são iguais em diversas distribuições.
Uso para automação de processos através dos comandos, facilita o trabalho no Sistema para Profissionais da Área.
O Terminal pode ser aberto de diversas formas, mas a sequência de teclas CTRL + ALT + T facilita seu acesso.
Dentro do terminal a sequência de teclas CTRL + SHIFT + T abre uma nova aba.
O comando pwd mostra o caminho do diretório.
$ pwd
O comando ls lista os diretórios e arquivos da pasta. O comando dir pode ser usado também, mas o comando anterior funciona melhor.
$ ls
O comando cd (change directory) muda o diretório atual, ou seja, muda o caminho, podemos entrar e sair de pastas.
$ cd
O comando mkdir (make directory) cria um diretório de arquivos, uma pasta.
$ mkdir teste
Para sair da pasta atual e retornar para a anterior é só digitar o comando cd ...
Linux
Tempo estimado de leitura: 1min
Da mesma forma que o Windows e o Mac OS, Linux é o sistema operacional, é o programa dentro do seu computador responsável pela comunicação dos hardwares, como mouse e teclado, e outros softwares que você instala. O Kernel do Linux, ou conjunto do Kernel, são conjuntos de instruções responsáveis por como será usado funções como memória, processador, periféricos e disco. Ele é o software que atua em todo sistema operacional (SO) e através das instruções repassadas ele cuida da forma como se comporta o computador.
Além do Kernel é necessário um conjunto de outros programas adicionais para podermos utilizar essa SO com mais efetividade, dentre esses interpretadores, editores de texto, e compiladores para que seja possível o desenvolvimento de outros programas. O desenvolvimento dos principais programas responsáveis pela interação com o Kernel são de autoria da fundação GNU. É por conta disso que muita gente se referencia ao Linux como GNU/Linux.
Por que utilizar?
Caso pare um instate para pesquisar a respeito, vai encontrar algumas páginas comparando o Linux com outros sistemas operacionais, principalmente com o windows. No geral tem várias vantagens, principalmente atreladas a desempenho, e por se tratar de um software livre, centenas de desenvolvedores já trabalharam no Linux buscando por melhorias que acreditavam poder acrescer nesse sistema operacional.
Distribuições
Por haver tanta gente trabalhando e desenvolvendo programas, acabou surgindo alguns flavors (sabores), que nada mais são que distribuições com características diferentes.
É como se te fornecessem uma variação de uma mesma coisa. Acaba que isso influencia em coisas como interface, e conjunto de programas que são inseridos junto com as instalações.
É um pouco difícil de dizer se existe uma melhor do que a outra, na verdade a melhor acaba sendo uma que você tenha mais familiaridade. Então leia um pouco sobre algumas para poder ver se encontra uma que acredite ser mais a sua cara.
WSL - Windows Subsystem for Linux
Tempo estimado de leitura: 1min
Esta é uma opção para pessoas que ao invés de migrar para outro sistema operacional, prefere desenvolver e usufruir de um terminal Linux, dentro do seu Windows.
Guia de instalação do Subsistema Windows para Linux
Basicamente é uma forma de se utilizar o terminal do Linux dentro de um subsistema windows.
Dual Boot
Tempo estimado de leitura: 4min
Esse passo tem a inteção de explicar como vai ser a instalação de outro sistema operacional dentro do seu computador, para não ter que abrir mão de uma interface que já é uma amiga de longa data, mas quer também exeperimentar a possibilidade de ter uma nova opção para desenvolver.
Começando
Warning: Antes de mais nada, faça esse passo a passo num dia calmo e que esteja tranquilo e disposto a possivelmente encontrar alguns problemas.
Esse tutorial segue um fluxo simples e contínuo para instalação do Ubuntu, caso se interesse por outra distribuição do Linux, aconselho a pesquisar um pouco, mas caso seja essa mesmo que gostaria, vamos para o tutorial! :)
-
Faça o download do Ubuntu (a 20.04 LTS é uma boa opção).
-
Tenha certeza de que tem ao menos 50 GB de espaço sobrando no seu HD.
-
Uma unidade flash USB com no mínimo 8 GB.
-
E um programa para para poder criar um USB bootável, uma sugestão seria o Rufus
1º passo: Crie um USB bootável com o Ubuntu
Antes de começar esse passo certifique-se de que não há nenhum arquivo importante dentro do seu pendrive, já que esse procedimento irá ser reescrito fazendo com que perca qualquer conteúdo que havia contido antigamente.
Com seu pendrive pronto para ser reescrito, insira-o em seu computador e abra o Rufus.
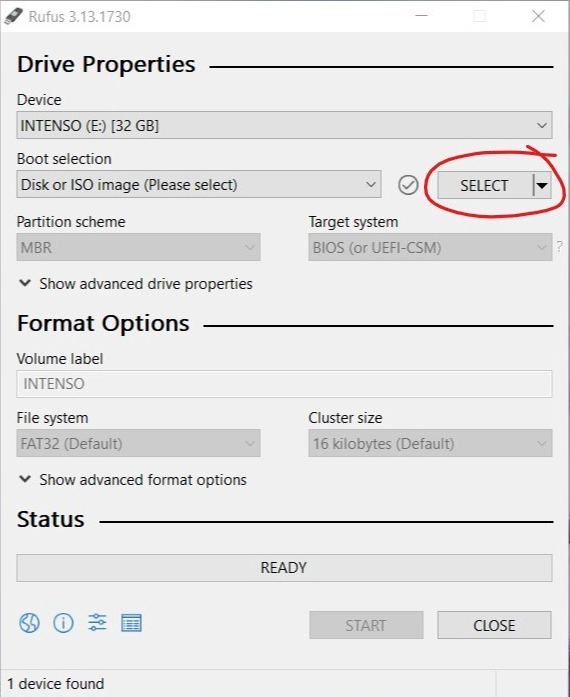
Ele irá detectar automaticamente o drive USB inserido.
Em 'Boot selection' selecione a imagem ISO do Ubuntu que havia feito o download anteriormente. Depois que selecionar irá aparecer alguns avisose uma opção de escrita da ISO. Responda 'yes', escolha a opção recomendada, e confirme que está ciente que os arquivos dentro da unidade serão destruídos.
Depois disso o botão de "Ready", vai ser habilitado. Clique e espere alguns minutos enquanto o USB vai sendo reescrito. Isso pode demorar alguns minutos dependendo da velocidade do seu USB.
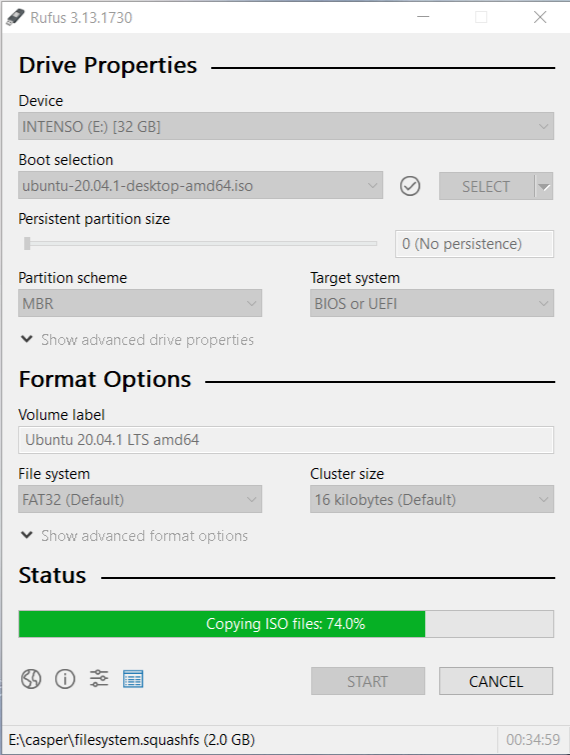
Quando terminar, remova seu USB de forma segura, agora dentro dele existe uma imagem de Ubuntu pronta para ser instalada em um computador.
Embora não seja exatamente necessário, recomenda-se desfragmentar o disco do seu computador para poder consolidar os arquivos do seu computador para o 'início' do seu disco, dessa forma liberando mais espaço antes de fazer o particionamento.
2º passo: Aloque espaço no seu disco rígido.
É necessário particionar seu disco rígido para separar um espaço de atuação para o novo sistema operacional que será instalado no seu computador.
Vá no menu iniciar do windows e procure por "Partições" ou por "Gerenciamento de disco".
Vai se deparar com uma tela similar a esta, nela vai listar as unidades de espaço contidas dentro do seu computador.
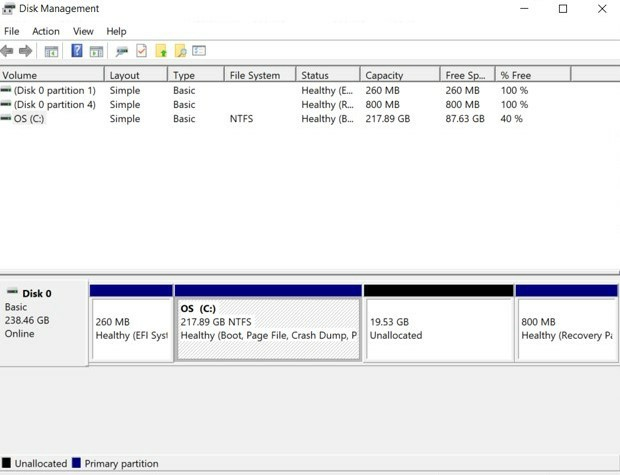
Escolha algum dos espaços tendo em mente que você irá dividir uma dessas unidades, caso tenha mais de uma, opte pela maior provavelmente a sua unidade "(C:)".
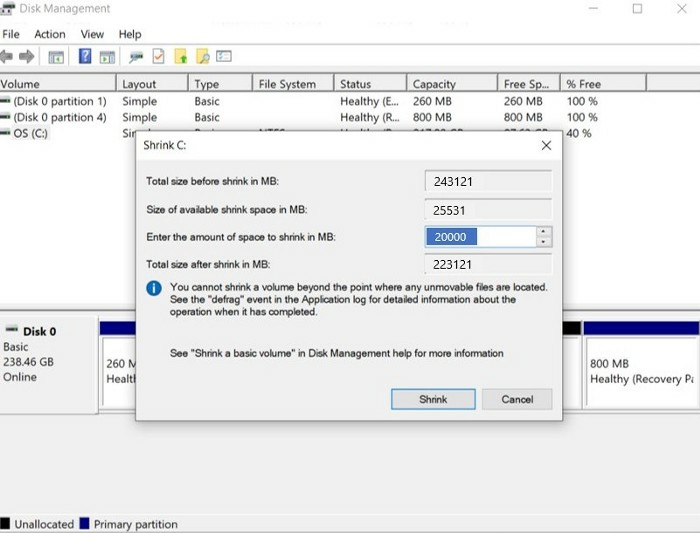
Clique com o botão direito na que escolheu. Clique em "Diminuir Volume...".
O espaço de disco que o Ubuntu LTS costuma requisitar, gira em torno de 20 GB ou mais.
Tenha em mente que por mais que ele precise apenas de pouco espaço, vai ser um outro sistema operacional onde irá precisar instalar softwares e salvar arquivos, logo é bom se reservar uma boa quantidade de espaço para não ter problemas por falta dele no futuro
Logo o espaço que irá diminuir seria de ao menos 20000 MB.
3º passo: Instalação.
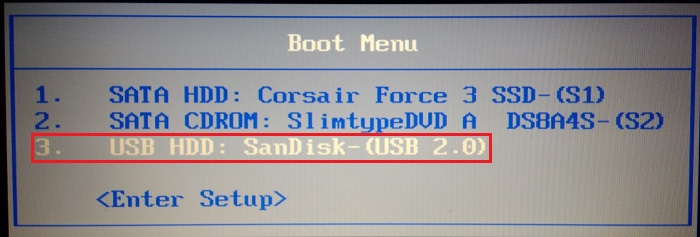
Coloque o Pendrive de com o Boot do Ubuntu em uma unidade USB do seu computador e o reinicie. Enqaunto ele estiver fazendo o processo de "Ligar" novamente, PRESSIONE VÁRIAS VEZES a tecla F11 ou F12 (na verdade pode variar até mesmo para as teclas F10, F8, F2, já que é uma coisa diferente desde a fabricação do computador), então caso não consiga chegar até a sua tela de bios, basta reiniciar novamente e escolher outra tecla.
Obtendo êxito, use as teclas do seu teclado para acessar o Boot Menu (menu de boot) e escolher o seu pendrive de boot, que nesse caso é o "3. USB HDD: SanDisk-(USB 2.0)".
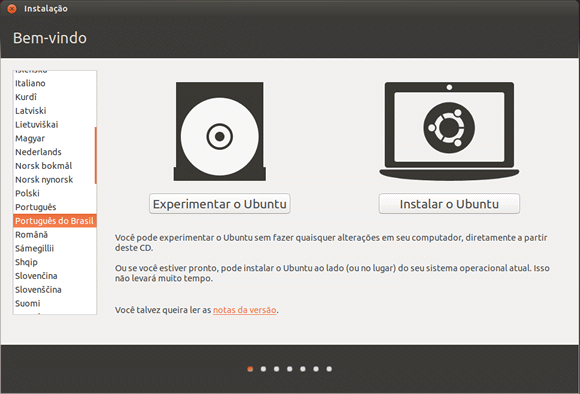
Sempre selecionando as opções e clicando em Continuar
Dessa forma o processo de instalação do Ubuntu será iniciado e poderá escolher qual idioma gostaria de fazer o processo de instalação.
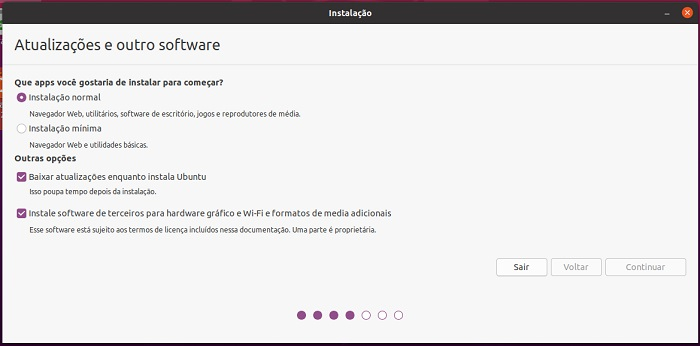
Depois poderá escolher a opção do Layout do seu teclado;
Irá escolher entre a instalação normal e a instalação mínima, e dependendo se já efetuou a configuração da sua internet, opte por selecionar as opções que baixa as atualizações juntamente com a instalação do Ubuntu.
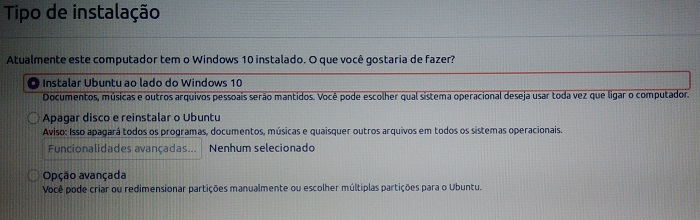
Escolha a sua localidade;
Defina as suas credenciais de nome, usuário e senha;
Espere as etapas finais da instalação e ao fim clique no botão "Reiniciar agora".
Lempre-se de desconectar o seu pen-drive antes de reiniciar
Quando terminar de reiniciar irá se deparar com uma tela indicando que conseguiu chegar ao enfim dual boot :)
Terminal
Tempo estimado de leitura: 11min
Por não possuir uma interface gráfica, a primeiro contato pode ser intimidador, mas é essencial saber ao menos o básico do terminal para interagir de forma mais prática com seu computador. Neste tópico vamos ensinar e explicar alguns comandos simples, que, no primeiro momento, vão ser de grande ajuda para iniciantes no assunto.
Experimente abrir o terminal e vamos fazer algumas experimentações;
No windows você tinha um gerenciador de tarefas, uma interface que te mostrava como funcionava a estrutura da organização dos seus arquivos, assim podendo entrar e sair de pastas, e acessar esses arquivos, executar, abrir, editar...
A primeira vista vai reparar no símbolo
~no começo da primeira linha, basicamente é uma abreviação para a sua pasta home no terminal.
Diretórios
Com o terminal aberto, utilize o comando cd (change directory) para alterar o diretório atual, com o acréssimo de / você pode acessar os arquivos de sistema do seu computador, então no seu terminal, experimente:
$ cd /
Bem nesse ponto haverá um símbolo
~$no começo do seu terminal, indicando uma nova linha de comando, a frente do sinal de$será o local onde há de ser inserido novos comandos, ao entrar em novas pastas/diretórios/a frente do sinal de~indicando qual a pasta em que você se encontra no momento.
Agora escreva ls (list contents) para poder listar pastas e arquivos dentro daquele diretório. Então dentro da pasta / experimente usar ls:
$ ls
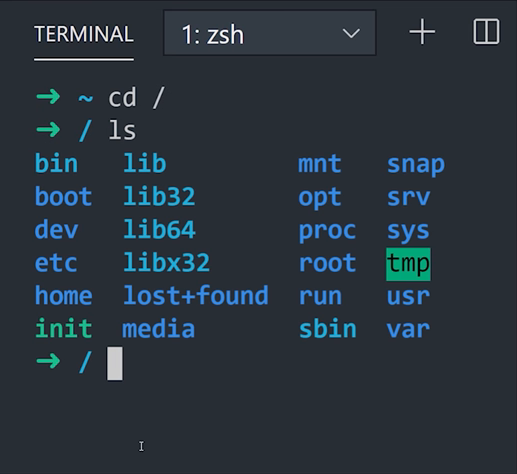
Nesse ponto você pode por exemplo tentar entrar em uma pasta dentro dessa pasta utilizando cd ali acima, junto com o nome de uma pasta presente dentro daquele diretório (que você acabou de ver usando o ls).
$ cd bin
Experimente mais uma vez listar os arquivos dentro desse outro diretório.
O diretório /bin contém os comandos binários essenciais (programas) que devem estar presentes quando o sistema é montado no modo para usuário único. Os aplicativos (como o Chrome, ) são armazenados em /usr/bin, enquanto os programas importantes do sistema e utilitários, como o shell bash, ficam localizados em /bin. O diretório /urs pode ser armazenado em outra partição. Por isso, colocar esses arquivos no diretório /bin garante que o sistema terá os programas mais importantes, mesmo se não houver outros sistemas de arquivos montados. O diretório /sbin é semelhante, pois ele contém os arquivos binários para a administração do sistema.
Bem, sabendo que, independente do seu sistema operacional as pastas do seu computador se comportam como uma árvore, e possuem uma certa hierarquia quanto a sua importância. Isso acontece para que haja uma certa segurança quando formos manipular alguns arquivos. Já que os programas mais importantes para o funcionamento estão no root do computador, e uma de suas ramificações é responsável pelas aplicações instaladas pelo usuário, sendo a nossa usr/bin.
Além da pasta bin que guarda arquivos binários para execução na root, vamos citar alguns outros que provavelmente vai se deparar com eles e se perguntar, sua função ou necessidade, até porque eles também estão consumindo uma parte da "memória" do seu computador.
/sbin: Da mesma forma que a bin, a sbin são conjuntos de executáveis do sistema que cuidam de configurações como a segurança do computador por exemplo. É responsável por pedir credenciais ou permissão de um adm quando for instalar algum programa por exemplo.
/boot: Se chegou a fazer o processo de dual boot, já tem uma ideia do que é guardado aqui dentro. Bem basicamente é tudo que o seu computador precisa para poder iniciar o seu Linux corretamente.
/dev: Como uma abreviação para developers, nessa pasta estão guardadas os arquivos responsáveis pelas configurações de desenvolvedores, no geral a conversa que ocorre entre hardwares como o seu teclado, mouse, câmera, com outras partes do seu computador.
/etc: Guarda também um conjunto de instruções que podem ser configuradas por texto, são tão importantes quanto os arquivos contidos em dev, entretanto podem ser simplesmente serem editados em um editor de texto do seu computador.
/home: Por default, praticamente sempre que abre o seu terminal começa nessa pasta, então funciona quase como o desktop do seu windows.
/lib(32 e 64): É onde as aplicações guardam arquivos ao se instalarem. Serão armazedos arquivos binários como em bin e sbin.
/media e /mnt: São diretórios em que você pode montar um dispositivo físico, como CD-ROM, partição do seu HD, um pendrive etc.
Executáveis
São os arquivos binários que execumatos ao utilizar um . antes do arquivo, algo como ./nomedoarquivo.
Já que temos várias pastas para guardar arquivos, e nem sempre sabemos onde foi parar aquele executável... Bem, dá para adotar algumas estratégias de como podemos agir a partir daqui.
Uma forma interessante de fazer com que o Linux mapeie arquivos executáveis a partir de uma pasta é utilizar o comando echo $PATH.
$ echo $PATH
Isso fará com que seja listado os PATH (que é aquele 'caminho' da 'URL') de onde possuem pastas com executáveis.
Caso queira saber onde contém um binário específico:
$ which curl
Onde which é a abreviação de Which binary is this, e curl o executável que estamos procurando. O retorno vai ser o PATH desse executável.
Instalando um software
Você também pode usar o terminal para instalar programas facilmente. Isso é especialmente útil se o software não está iniciando a instalação sozinho ou se você só quer agilizar o processo.
Para fazer isso, digite o comando sudo apt-get install nome e substitua o “nome” que colocamos no exemplo pelo nome do programa que você quer instalar. Em seguida, é só apertar o “Enter”.
$ sudo apt-get install nome
+ Comandos
sudo: permissões
Por razões de segurança, o Linux trabalha com permissões de usuários. Por isso, determinados comandos ou arquivos são acessíveis apenas pelo próprio dono ou pelo usuário administrador (root). Para que você não tenha que trocar de usuário a todo instante, existe o comando sudo, que garante credenciais de usuário root temporariamente, mediante a informação de uma senha (sua senha de usuário do seu Ubuntu).
Para fazer o teste, tente executar o comando:
$ ls /root
Você reberá um aviso de permissão negada. Em seguida, execute:
$ sudo ls /root
Depois de informar a senha do seu próprio usuário (no caso do Ubuntu), o comando será executado normalmente e os arquivos a pasta root serão listados no terminal.
É equivalente ao executar um programa como administrador no Windows.
man: manual dos comandos
O comando man é a abreviação de manual, basicamente, se precisar saber todas as coisas referentes aquele comando, experimente utilizar o comando man na frente dele adicionar o comando que quer saber sobre.
$ man ls
Criar uma pasta naquele diretório
$ mkdir nome_da_pasta
Executar um arquivo
$ ./nome_do_arquivo
Apagar um arquivo
$ rm nome_arquivo
caso o arquivo não esteja na pasta em que está no momento, basta colocar o caminho antes do nome.
$ rm /caminho/nome_arquivo
cada
/representa um caminho antes de uma pasta
cp: copiar
Copiar um arquivo utilizando o terminal é bem simples. Use o comando cp seguindo do arquivo de origem e o destino para ele, que pode ser tanto uma nova pasta quanto também um novo arquivo, com nome diferente. Exemplo:
$ cp arquivo1.txt arquivo2.txt
$ cp arquivo1.txt pastanova/
Caso a intenção seja de copiar um diretório inteiro, basta inserir o parâmetro
-r. Se quiser clonar uma pasta, use:
$ cp -r pasta1 pasta2
cal: calendário
Um simples comando que pode ser usado para abrir o calendário automaticamente é o cal.
$ cal
cmp: comparar arquivos
Se usar o comando cmp e listar dois arquivos em seguida, o terminal se encarregará de compará-los automaticamente.
$ cmp arquivo1.txt arquivo2.txt
mv: mover
Para mover arquivos existe o comando mv e ele pode ser usado tanto para remanejar arquivos como para renomeá-los. Se quiser enviar o arquivo de uma pasta para outra, basta seguir o exemplo:
$ mv pasta1/arquivo1 pasta2/
Se preferir apenas renomeá-lo:
$ mv arquivo1 arquivo2
more: ler
Caso você precise ler o conteúdo de um arquivo de texto, use o comando more seguido do caminho e nome do arquivo:
$ more /home/user/arquivo.txt
Todo conteúdo do arquivo será exibido no terminal, preenchendo a tela com texto. Para prosseguir com a leitura, pressione a barra de espaço e, caso precise voltar uma ou mais páginas, use a tecla "b". Se quiser sair antes do fim do arquivo, pressione "q". Leitura de texto no Linux com o comando more.
df: conferir o espaço em disco
Quer saber qual é o espaço total e quantos GB disponíveis existem em cada partição do sistema? Use o comando df -h .
$ df -h
A opção -h, aliás, quer dizer human-readable, ou seja, legível para humanos. Se você executar o comando sem ela, as informações serão exibidas em kilobytes e será necessário convertê-las mentalmente para outras unidades.
free: ver uso de memória
Se quiser dar uma rápida olhada no uso de memória do seu computador, basta abrir o terminal e inserir o comando free e apertar a tecla Enter. Dessa forma, poderá encontrar aplicações que estão consumindo mais memória, ideal para identificar fontes de problemas.
$ free
history: histórico de comandos
Para ter uma visualização dos comandos que você usou no terminal previamente, simplesmente insira o comando history.
$ history
locate: encontrar arquivos
Para encontrar arquivos no Linux com facilidade, basta inserir o comando locate seguido pelo nome dos arquivos que você achar.
$ locate arquivo1.txt
grep: buscas em textos
Imagine a seguinte situação: você tem um arquivo .txt com vários nomes de alunos de certa escola, mas não tem certeza se um nome em específico está listado. O grep ajuda você a procurar por esse aluno e a fazer muito mais com a ajuda de expressões regulares.
Bastaria executar o comando:
$ grep "Nome do Aluno" arquivo.txt
Fará com que o terminal busque pelo nome indicado dentro da relação.
Caso você não tenha certeza se o nome do aluno foi escrito respeitando as letras maiúsculas, adicione o parâmetro -i para que grep passe a ignorar essa distinção durante a busca.
clear: limpar buffer
Por último, um comando que ajuda a organizar um pouco a confusão de letras que ficam no terminal depois de horas de uso. Para limpar toda a ela, execute o comando clear. Depois, é só voltar a usar o terminal normalmente, como se nada tivesse acontecido.
$ clear
Ou então, pode utilizar o comando
Ctrl + Lpara a mesma coisa.
Atalhos
Alguns atalhos que podem facilitar o manuseio dentro do terminal:
tab : Ele irá automaticamente completar o que você estava digitando ou mostrará todos os resultados possíveis.
Ctrl+L : Para limpar o terminal.
Ctrl+A : Este atalho moverá o cursor para o início da linha. Suponha que você digitou um longo comando ou caminho no terminal e deseja ir para o início dele. Se usar a tecla de seta para mover o cursor levará bastante tempo.
Ctrl+E : Esse atalho é oposto ao Ctrl + A. O Ctrl + A envia o cursor para o início da linha, enquanto Ctrl + E move o cursor para o final da linha.
Ctrl+C : Cancela o comando atual em funcionamento.
Ctrl+Z : Pausa o comando atual, em primeiro plano ou segundo plano.
Ctrl+D : Faz o logout da sessão atual (fecha o terminal).
Ctrl+W : Apaga uma palavra na linha atual.
Ctrl+U : Apaga a linha inteira.
Ctrl+K : Este é semelhante ao atalho Ctrl + U. A única diferença é que, em vez do início da linha, ela apaga tudo, da posição atual do cursor até o final da linha.
Ctrl+Y : Isto irá colar o texto apagado ao usar os atalhos Ctrl + W, Ctrl + U e Ctrl + K. Útil no caso de você ter apagado o texto errado ou se você precisar usar o texto apagado em outro lugar.
Ctrl+P : Você pode usar este atalho para visualizar o comando anterior. Você pode pressioná-lo repetidamente para continuar retornando ao histórico de comandos. Em muitos terminais, o mesmo pode ser alcançado com a tecla PgUp.
Ctrl+N : Você pode usar este atalho junto com o Ctrl + P. Ctrl + N exibe o próximo comando. Portanto, se você estiver visualizando comandos anteriores com Ctrl + P, poderá usar Ctrl + N para navegar para frente e para trás. Muitos terminais têm esse atalho mapeado para a chave PgDn.
Ctrl+R : Busca um comando recente.
!! : Repete o último comando.
exit : Faz o logout da sessão atual (fecha o terminal).
F.A.Q
Tempo estimado de leitura: 3min
As perguntas mais frequentes & votadas no Stackoverflow :^)
Linux
Bash
Ubuntu
Começando com Git
Tempo estimado de leitura: 1min
Vamos começar sua jornada com Git! Há muita coisa a se aprender, mas toda caminhada tem um ponto de partido. Nesse capítulo, discutiremos sobre:
- Resumão
- O que é git & Github?
- Instalação e Configuração
- Principais comandos
- + Comandos
- Sugestões de aliases/functions
- FAQ
Resumão
Tempo estimado de leitura: 1min
O que você verá nesse capítulo:
- Resumão
Explicação
| _ | O que é |
|---|---|
| Git | Ferramenta para "salvar" as varias versões dos seus arquivos/código-fonte |
| Github | Lugar pra salvar teus arquivos/código-fonte |
Flow básico de utilização
1. Após criar repositório no Github, no terminal
Clonar um repositório
$ git clone <endereço do novo repositório>
Trocar de diretório
$ cd <nome do repositorio>
Exemplo completo
# ex:
# git clone https://github.com/airbnb/javascript
# cd javascript
2. Após fazer as mudanças nos arquivos que quiser, no terminal
Listar todas as alterações feitas (o que foi adicionado/modificado/removido)
$ git status
Adicionar alterações feitas
$ git add <arquivo_1> <arquivo_2>
Commitar
$ git commit -m "mensagem explicando o proposito desse commit"
Subir as alterações pro Github
$ git push origin <branch_desejada>
Exemplo completo
# ex:
# git add RemoveUserButton.js styles.css
# git commit -m "adicionando botão para remoção de usuários"
# git push origin main
Git & Github
Tempo estimado de leitura: 1min
Git
Lembra quando salvava os arquivos como projeto-final.txt, projeto-final-2.txt, projeto-final-mesmo_agora_vai.txt (etc)?
Git soluciona isso. Serve justamente pra versionar seus arquivos (além de providenciar varias outras utilidades como consequencia disso), mas de uma forma muito mais elegante.
Considerando aquele exemplo besta acima, suponha que cada um dos arquivos possua os seguintes conteúdos:
-
projeto-final.txtAmanhã será um dia bonito -
projeto-final-2.txtAmanhã será um belíssimo dia! -
projeto-final-mesmo_agora_vai.txtOs dias porvir hão de ser belos!
Utilizando git, considerando essa linha do tempo, você poderia ter apenas um arquivo (projeto-final.txt [com o conteúdo de projeto-final-mesmo_agora_vai.txt]), com a opção de retornar ao conteúdo das versões anteriores sempre que quisesse.
Além disso, Git possui algo muito incrível que é o sistema de Branches (traduzindo, seriam "galhos" ou "ramificações"); isso é, você pode criar branches independentes com propósitos distintos (por exemplo: uma branch com código mais estavel, outra para experimentações e ai vai da imaginação [ou não])
Tudo isso ficará mais claro conforme formos praticando :)
Github
Bom, todo esse versionamento é incrivel; mas ele funciona somente localmente. Github surge, portanto, para armazenar repositórios online; dessa forma possibilita que:
- Você possa recuperar seu repositório/código para trabalhar em outros computadores
- Você possa compartilhar seu código com outras pessoas de forma que ambos trabalharão na mesma base de código, cada um podendo inserir seus próprios versionamentos (ou, commits).
Instalação e Configuração
Tempo estimado de leitura: 4min
O que você verá nesse capítulo:
Instalando
Windows
Para Windows, não tem segredo, basta simplesmente baixar o GitBash :)
Linux
Via de regra, voce pode replicar todos os comandos aqui no Mac; basta substituir os "
sudo apt install ..." por "brew install ..."
-
Por ser muito comum, provavelmente o
gitjá virá instalado no seu Linux; para averiguar, basta rodar, no seu terminal:$ which git /usr/bin/git -
Caso o output tenha sido "
git not found", há de se instalar com*:$ sudo apt install git
* Dependendo do Linux utilizado, pode ser que o gerenciador de pacotes seja outro em vez do apt-get (ex: pacman)
Configurando
Primeiro, tendo em vista que o commit é um registro, é importante se identificar antes de começar a utilizar o git:
git config --global user.name "Seu Nome"
git config --global user.email seu_email@exemplo.com
# ex:
# git config --global user.name "Joao da Silva"
# git config --global user.email joao_da_silva@gmail.com
Caso queira adotar outras identidades em outras pastas de trabalho, basta replicar o comando acima sem a flag --global:
cd pasta_de_trabalho
git config user.name "Outro Nome"
git config user.email outro_email@exemplo.com
SSH
Caso esteja utilizando GitBash no Windows não precisa se preocupar com isso
Caso tenha utilizado git outras vezes, já deve ter percebido como é chato ter de se autenticar todas as vezes que vai subir um commit para o Github
Para contornar isso, vamos nos autenticar utilizando uma chave ssh
-
Verificar se já foram registradas chaves ssh para seu sistema operacional
$ ls -a ~/.ssh . .. id_rsa id_rsa.pub known_hosts -
Caso não hajam chaves neste diretorio, isto é, o output tenha sido
$ ls -a ~/.ssh . ..temos de criá-las.
No terminal:
-
Pressione [enter] quantas vezes for necessário
$ ssh-keygenPequena explicação: A flag '-s' gera um "script" bash pro stdout (em texto), necessário para conectar/iniciar o agente.
-
O eval, então, "roda" esses comandos do script
$ eval `ssh-agent -s` -
adicionar a chave pro agente (caso tenha atribuido outro nome [no "$ ssh-keygen"] para a chave privada, mude o "id_rsa" para o nome correto)
$ ssh-add ~/.ssh/id_rsa
-
-
Então, basta adicionar a chave pública no Github. Abra este link, clique no botão "New SSH Key", e então copie a sua chave pública em
~/.ssh/id_rsa.pub:esses comandos são totalmente dispensáveis, já que pode abrir o arquivo e copiar manualmente
-
Para copiar pro clipboard a chave publica
Instalar
xclip:$ sudo apt install xclipCopiar arquivo pro clipboard (o equivalente a dar Ctrl+C no conteúdo do arquivo)
$ xclip -sel c < ~/.ssh/id_rsa.pub -
Agora basta colar essa chave no campo adequado para criar a chave dentro do Github
-
-
Extra: Atualizar as urls dos repositorios clonados para utilizar o ssh em vez do https. Primeiro, checar como o repositório está rastreado.
- listar os repositórios rastreados
$ git remote -v origin https://github.com/appointment-octopus/ebook (fetch) origin https://github.com/appointment-octopus/ebook (push)Caso realmente esteja utilizando https (e deseje alterar para utilizar ssh), basta rodar, no terminal, o seguinte comando:
$ echo "$(git ls-remote --get-url origin)" |\ { read url;\ eval `git remote set-url origin git@github.com:${${url#*com/}%.git}.git`; }
Como curiosidade, como o comando anterior foi construído:
Tendo em vista que uma url https padrão do github é:
e uma url ssh padrão é:
git@github.com:appointment-octopus/ebook.git
percebemos que necessitamos extrair o nome da organização + nome do repositório; isto é: appointment-octopus/ebook. Utilizando o pattern matching para strings padrão do bash, conseguimos fazer isso. O # é utilizado para remover prefixos, então:
$ URL=https://github.com/appointment-octopus/ebook
O * vai ignorar qualquer caracter até encontrar a sequencia com/, e então retornar o resto da string
$ echo "${URL#*com/}"
Porém, algumas vezes a url https vem com um .git no final; para ignorá-lo, utilizaremos o %, cujo qual é utilizado para remover sufixos:
$ URL=appointment-octopus/ebook.git
Irá retornar a string até encontrar a sequencia ".git"
$ echo "${URL%.git}
Portanto, juntando tudo, fica:
$ URL=https://github.com/appointment-octopus/ebook.git
$ echo "${${URL#*com/}%.git}"
Entretanto, estamos inserindo a url na mão. Felizmente existe um comando que nos retorna a url que precisamos:
$ URL="$(git ls-remote --get-url origin)"
Agora que temos o que queríamos (nome do usuário/organização+nome do repositório), basta formatar o url de output.
$ URL="$(git ls-remote --get-url origin)"
$ echo "git@github.com:${${URL#*com/}%.git}.git"
Mas não basta ter a url formatada se não "setarmos" ela:
$ URL="$(git ls-remote --get-url origin)"
eval `git remote set-url origin git@github.com:${${URL#*com/}%.git}.git`
Juntando tudo em um comando só, utilizando o pipe ("|") do bash para passar a url para a variável url:
$ echo "$(git ls-remote --get-url origin)" |\
{ read url;\
eval `git remote set-url origin git@github.com:${${url#*com/}%.git}.git`; }
Principais comandos
Tempo estimado de leitura: 18min
Bom, enfim vamos trabalhar com um exemplo do zero.
O que você verá nesse capítulo:
- Principais comandos
Git init
Para este tutorial, crie uma pasta para que possa acompanhar esse tutorial de forma mais interativa:
$ mkdir aprendendo_git
$ cd aprendendo_git
Para versionar uma pasta/diretório, é preciso iniciar um repositório. A partir da pasta raíz do seu projeto, execute:
$ git init
Initialized empty Git repository in <caminho_até_diretório>/aprendendo_git/.git/
Após isso, liste os arquivos neste diretório:
$ ls -a
. .. .git
a flag
-asignifica: "do not ignore entries starting with."
O Git criou uma pasta chamada .git. Essa pasta contém os metadados que o git necessita para operar naquele repositório.
Extra
Sinta-se, obviamente, a vontade para explorar essa pasta :)
$ sudo apt install tree
$ tree .git
.git
├── branches
├── config
├── description
├── HEAD
├── hooks
│ ├── applypatch-msg.sample
│ ├── commit-msg.sample
│ ├── fsmonitor-watchman.sample
│ ├── post-update.sample
│ ├── pre-applypatch.sample
│ ├── pre-commit.sample
│ ├── pre-merge-commit.sample
│ ├── prepare-commit-msg.sample
│ ├── pre-push.sample
│ ├── pre-rebase.sample
│ ├── pre-receive.sample
│ └── update.sample
├── info
│ └── exclude
├── objects
│ ├── info
│ └── pack
└── refs
├── heads
└── tags
9 directories, 16 files
Git status
Sempre que você estiver nesse repositório, terá acesso a versão mais atual do projeto. Utilizando o comando git status, pode aferir quais foram as ultimas mudanças em relação ao ultimo commit (traduzindo: a ultima versão "salva" do projeto)
Como não adicionamos nenhum arquivo, caso rode este comando terá o seguinte output:
$ git status
On branch master
No commits yet
nothing to commit (create/copy files and use "git add" to track)
hoje em dia há um movimento para que a branch padrão se chame
mainem vez demaster, então não se surpreenda caso o seu output tenha sido diferente
Ou seja, não há nada para adicionar (e depois commitar), assim como não há uma versão anterior para se comparar com a versão atual da pasta
Git add
Crie um arquivo lorem_ipsum.txt:
$ echo "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Mauris malesuada augue vel quam dignissim, nec egestas nisl pretium. Integer porttitor eleifend turpis non ullamcorper. Maecenas maximus sit amet ipsum et facilisis. Aenean tincidunt urna a ex consequat venenatis. Curabitur eget ante scelerisque tellus efficitur pulvinar ac quis lorem. Donec imperdiet ligula id tortor viverra, imperdiet consequat est suscipit. Donec congue pellentesque velit eget rhoncus. Vestibulum bibendum erat sem, sed maximus ipsum condimentum et. Vivamus lectus justo, hendrerit ac ornare eget, ultrices ut massa. Sed euismod, magna vitae ultrices aliquam, est quam volutpat mauris, id fringilla mauris sem ut diam. Mauris laoreet efficitur urna at tempor. Nulla scelerisque iaculis ligula et consequat. Nulla in viverra nunc. Nunc nibh neque, ornare ut magna sed, tempor egestas ligula. Quisque iaculis justo ut diam mattis, vitae iaculis eros luctus." > lorem_ipsum.txt
Verifique que o mesmo foi criado:
$ ls
lorem_ipsum.txt
Entretanto, o mesmo ainda não está sendo rastreado pelo Git:
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
lorem_ipsum.txt
nothing added to commit but untracked files present (use "git add" to track)
Perceba que o próprio git nos dá dicas. Adicione o arquivo a zona de "staging": uma pre-seleção do que deverá, de fato, ser versionado/commitado.
$ git add lorem_ipsum.txt
O arquivo não foi adicionado, ainda, ao repositório do git. A zona de staging é um intermediário entre o Local e o Repositório.
O status mudou:
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: lorem_ipsum.txt
Git commit
Vamos, então, commitar o arquivo: ou seja, adicionar ao repositório do git para que o mesmo comece a ser versionado.
$ git commit -m "Adiçionando arquivo Lorem Ipsum de 1 paragrafo"
O status, novamente, mudou:
$ git status
On branch master
nothing to commit, working tree clean
Git log/reflog
Para verificar quais commits já fizera, basta rodar o comando log:
$ git log
commit 0e1027f301d18c72e37a755775e8c189a79823e3 (HEAD -> master)
Author: Seu Nome <seu@email.com>
Date: Thu Mar 18 02:03:29 2021 -0300
Adiçionando arquivo Lorem Ipsum de 1 paragrafo
Perceba que é informado qual o "id"/hash desse commit (0e1027f301d18c72e37a755775e8c189a79823e3), o autor do commit, data e a mensagem inserida -- todas as informações necessárias para rastrear esse versionamento do repositório.
Se utilizar reflog, terá um log mais enxuto (com hashs encurtecidas também):
$ git reflog
0e1027f (HEAD -> master) HEAD@{0}: commit (initial): Adicionando arquivo Lorem Ipsum de 1 paragrafo
Note que o início de ambas as hashs são iguais
O log têm inumeras utilidades que serão abordadas no próximo capítulo :)
Git commit --amend
Como pôde perceber, há um erro ortográfico na mensagem do commit: escrevemos "Adiçionando" em vez de "Adicionando". Podemos alterá-la utilizando o comando --amend:
$ git commit --amend
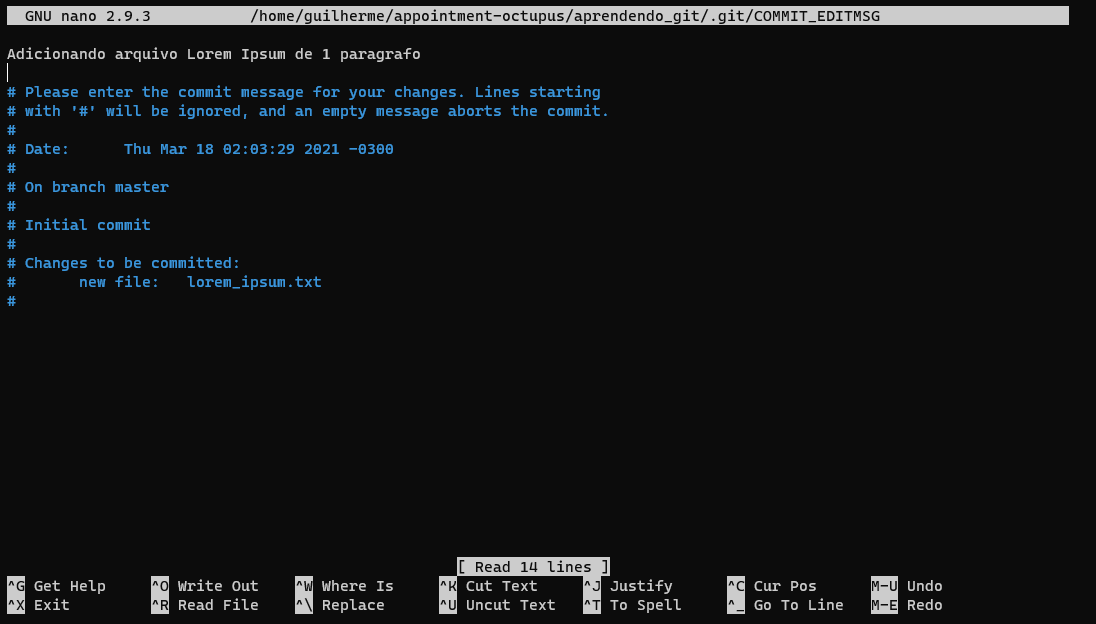
Este editor pode parecer estranho a primeira vista. Se chama nano, e vem como editor de texto padrão no terminal do Linux.
Após fazer a alteração necessária, basta apertar Ctrl+O e [Enter] para salvar a alteração no commit, e Ctrl+X para retornar ao terminal.
Vale ressaltar que esse comando vale não somente para a mensagem do commit como, também, para os arquivos. Bastaria modificar o que fosse conveniente, utilizar git add e então git commit --amend.
message
Além disso, caso queira evitar utilizar o nano, basta incluir a flag -m:
A titulo de exemplo, vamos criar o arquivo backup-lorem_ipsum.txt:
$ cp lorem_ipsum.txt backup-lorem_ipsum.txt
Status:
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
backup-lorem_ipsum.txt
nothing added to commit but untracked files present (use "git add" to track)
Adicionando-o:
$ git add backup-lorem_ipsum.txt
Commitando:
$ git commit --amend -m "Adicionando arquivo Lorem Ipsum de 1 paragrafo e, também, arquivo de backup"
[master 6e3bfef] Adicionando arquivo Lorem Ipsum de 1 paragrafo e, também, arquivo de backup
Date: Thu Mar 18 02:03:29 2021 -0300
2 files changed, 2 insertions(+)
create mode 100644 backup-lorem_ipsum.txt
create mode 100644 lorem_ipsum.txt
Log:
$ git log
commit 6e3bfef34d498057d67454c88188885dd82bec7f (HEAD -> master)
Author: Seu Nome <seu@email.com>
Date: Thu Mar 18 02:03:29 2021 -0300
Adicionando arquivo Lorem Ipsum de 1 paragrafo e, também, arquivo de backup
no-edit
Acaso queira modificar só os arquivos (e, não, a mensagem do commit), basta incluir a flag --no-edit.
Boas praticas
É interessante que só se faça isso em commits locais, haja vista que o commit "amendado" é outro commit, distinto do que fora utilizado como base. Isso significa que, caso este seja um commit publico, ao "adulterá-lo", tende a gerar uma inconveniência para outros desenvolvedores que estavam codando a partir daquele commit.
Além disso, para "subir" este commit (ver git push), você terá de usar a flag -f (force), que é extremamente perigosa de se utilizar em um repositório que multiplas pessoas estão trabalhando, já que força a sobreescrever qualquer commit que esteja la; isso significa que há grandes chances de você apagar o trabalho de outros colegas, além de dificultar a recuperação dos commits perdidos.
Git reset/restore
Seguindo a partir do exemplo anterior, não iremos utilizar o arquivo backup-lorem_ipsum.txt; vamos ver como está o nosso reflog:
$ git reflog
7bc9a79 (HEAD -> master) HEAD@{0}: commit (amend): Adicionando arquivo Lorem Ipsum de 1 paragrafo e, também, arquivo de backup
23d7a38 HEAD@{1}: commit (amend): Adicionando arquivo Lorem Ipsum de 1 paragrafo
4a6b384 HEAD@{2}: commit (initial): Adiçionando arquivo Lorem Ipsum de 1 paragrafo
já o log:
commit 7bc9a79b8c88160de6fc64f4a9f465fb52f7fcee (HEAD -> master)
Author: Seu Nome <seu@email.com>
Date: Thu Mar 25 16:56:37 2021 -0300
Adicionando arquivo Lorem Ipsum de 1 paragrafo e, também, arquivo de backup
Para retornamos ao estado anterior, iremos utilizar o comando git reset:
-
utilizando a flag
--soft:O que ela faz? Retorna ao commit anterior, sem tocar nos arquivos
$ git reset --soft HEAD@{1}$ ls backup-lorem_ipsum.txt lorem_ipsum.txt$ git status On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage) new file: backup-lorem_ipsum.txt$ git log commit 23d7a38445227f7ca71667945b66cd04d9c86c23 (HEAD -> master) Author: Guilherme de Lyra <guilyra12@gmail.com> Date: Thu Mar 25 16:56:37 2021 -0300 Adicionando arquivo Lorem Ipsum de 1 paragrafo -
utilizando a flag
--hard:O que ela faz? Retorna ao estado identico do commit anterior, modificando/removendo arquivos se necessário.
$ git reset --hard HEAD@{1}$ ls lorem_ipsum.txt$ git status On branch master nothing to commit, working tree clean$ git log commit 23d7a38445227f7ca71667945b66cd04d9c86c23 (HEAD -> master) Author: Guilherme de Lyra <guilyra12@gmail.com> Date: Thu Mar 25 16:56:37 2021 -0300 Adicionando arquivo Lorem Ipsum de 1 paragrafo
Git remote
Bom, o primeiro passo é criar sua conta no Github. Após isso, crie um novo repositório:
Agora, basta adicionar esse endereço ao nosso repositório git local:
* repare que você têm de substituir seu nome na URL abaixo
$ git remote add origin https://github.com/<seu nome de usuário>/aprendendo-git
o termo "origin" é o mais adotado para nomear os endereços dos repositórios rastreados, mas fica a seu critério escolher outro nome.
A titulo de exemplo, vamos adicionar o mesmo endereço mas em formato ssh em vez de https:
$ git remote add origin-ssh git@github.com:<seu nome de usuário>/aprendendo-git.git
Feito isso, você pode listar todos os endereços mapeados utilizando a flag -v:
$ git remote -v
origin https://github.com/<seu nome de usuário>/aprendendo-git (fetch)
origin https://github.com/<seu nome de usuário>/aprendendo-git (push)
origin-ssh git@github.com:<seu nome de usuário>/aprendendo-git.git (fetch)
origin-ssh git@github.com:<seu nome de usuário>/aprendendo-git.git (push)
Git branch
Para nos atermos aos padrões atuais de nome para a branch padrão (main em vez de master), utilizaremos o comando:
$ git branch -M main
a flag
-Msignifica--force--move: é um renomeamento forçado da branch atual. Pode-se, também, especificar qual é a branch que será renomeada:$ git branch -M master main
Git push
Agora que criamos o repositório e mapeamos-o, podemos "subir" o nosso repositório local pra "nuvem" Github:
$ git push -u origin main
Username for 'https://github.com': <seu nome de usuário>
Password for 'https://<seu nome de usuário>@github.com':
Counting objects: 3, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 741 bytes | 10.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/<seu nome de usuário>/aprendendo-git.git
* [new branch] main -> main
Branch 'main' set up to track remote branch 'main' from 'origin'.
a flag
-userve para indicar que este remoto (origin) será o padrão a ser utilizado nessa branch local; então quando for utilizar ogit pull, não precisará explicitar qual remoto & branch (ex:git pull origin main)
Agora, basta acessar a URL do seu repositório e verificar que o arquivo lorem_ipsum.txt está lá:
README.md
README.md se trata de um arquivo Markdown, uma linguagem de marcação de texto para criar textos formatados; este arquivo, neste contexto, é utilizado para descrever o propósito desse repositório. Vamos adiciona-lo pelo proprio Github. No site do seu repositório, clique no botão:
Descreva como preferir e insira uma mensagem de commit:
Resultado:

Criando mais um arquivo
Para enriquecer nosso exemplo, vamos commitar mais um arquivo. Vamos chamá-lo de lero_lero.txt:
$ echo "Podemos já vislumbrar o modo pelo qual a adoção de políticas descentralizadoras talvez venha a ressaltar a relatividade de alternativas às soluções ortodoxas." > lero_lero.txt
Adicionando para a área de staging:
$ git add lero_lero.txt
Commitando:
$ git commit -m "adicionando arquivo lero lero para enriquecer tutorial"
Subindo novamente para o Github :D
$ git push origin main
Username for 'https://github.com': <seu nome de usuário>
Password for 'https://<seu nome de usuário>@github.com':
To https://github.com/<seu nome de usuário>/aprendendo-git.git
! [rejected] main -> main (fetch first)
error: failed to push some refs to 'https://github.com/<seu nome de usuário>/aprendendo-git.git'
hint: Updates were rejected because the remote contains work that you do
hint: not have locally. This is usually caused by another repository pushing
hint: to the same ref. You may want to first integrate the remote changes
hint: (e.g., 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
Opa, deu erro! O erro nos diz que há alterações que estão na branch remota que não se encontram na sua branch local. Isso significa que, antes de subir nosso trabalho, precisamos atualizar nosso repositorio para que nenhum trabalho seja perdido (nesse caso, o README.md que está no repositório remoto).
Git pull
O git pull na verdade se trata de dois comandos em um só: git fetch e git merge.
O fetch serve para detectar as alterações que se encontram no repositório remoto cujo as quais ainda não foram mapeadas no repositório local:
$ git fetch origin main
Username for 'https://github.com': <seu nome de usuário>
Password for 'https://<seu nome de usuário>@github.com':
remote: Enumerating objects: 4, done.
remote: Counting objects: 100% (4/4), done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), done.
From https://github.com/<seu nome de usuário>/aprendendo-git
* branch main -> FETCH_HEAD
fc48527..fc0e748 main -> origin/main
Vejamos o status:
$ git status
On branch main
Your branch and 'origin/main' have diverged,
and have 1 and 1 different commits each, respectively.
(use "git pull" to merge the remote branch into yours)
nothing to commit, working tree clean
Git merge
Como vimos, as branchs remota e local não estão integradas, para sincronizarmos-as, iremos utilizar o comando merge:
*: o editor de texto nano aparecerá novamente, relembre dele aqui
$ git merge origin/main
Merge made by the 'recursive' strategy.
README.md | 3 +++
1 file changed, 3 insertions(+)
create mode 100644 README.md
Listando o diretório:
$ ls
README.md lero_lero.txt lorem_ipsum.txt
Log:
$ git log
commit 8e756f1edbac45f7626749340a1f7c4650433c99 (HEAD -> main)
Merge: 17cb2da fc0e748
Author: Guilherme de Lyra <guilyra12@gmail.com>
Date: Thu Mar 25 23:17:32 2021 -0300
Merge remote-tracking branch 'origin/main' into main
commit 17cb2da0dda74e14859546d9706b16cdbfcdb400
Author: Guilherme de Lyra <guilyra12@gmail.com>
Date: Thu Mar 25 23:07:10 2021 -0300
adicionando arquivo lero lero para enriquecer tutorial
commit fc0e7489c1886c98a55b6e7a4c71cb7f70f47d9a (origin/main)
Author: Guilherme de Lyra <guilyra12@gmail.com>
Date: Thu Mar 25 22:52:52 2021 -0300
Adicionando arquivo README
para melhor descrever o propósito deste repositório
commit fc4852752385dd2c0031fb493e2b9b6c851da514
Author: Guilherme de Lyra <guilyra12@gmail.com>
Date: Thu Mar 25 17:07:30 2021 -0300
Adicionando arquivo Lorem Ipsum de 1 paragrafo
Perceba que um commit "lixo" foi adicionado para indicar o merge entre as branchs.
Status:
$ git status
On branch main
Your branch is ahead of 'origin/main' by 2 commits.
(use "git push" to publish your local commits)
nothing to commit, working tree clean
Finalmente, agora, podemos então pushar/empurrar/subir o commit pro repositório remoto:
$ git push origin main
Username for 'https://github.com': <seu nome de usuário>
Password for 'https://<seu nome de usuário>@github.com':
Counting objects: 5, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (5/5), 778 bytes | 778.00 KiB/s, done.
Total 5 (delta 0), reused 0 (delta 0)
To https://github.com/<seu nome de usuário>/aprendendo-git.git
fc0e748..8e756f1 main -> main
Modificando arquivo remotamente e localmente, simultaneamente
Vamos abrir o arquivo lero_lero.txt e modificar seu conteúdo:
No repositorio local
*: lembrando que, se preferir, pode abrir o arquivo para alterá-lo manualmente.
$ sed -i 's/Podemos já vislumbrar/Abacate/g' lero_lero.txt
sed é um comando bem poderoso, vale a pena ~estudá-lo a parte; mas, basicamente, o comando recebe um "padrão" para encontrar (nesse caso "Podemos já vislumbrar") e qual padrão haverá de se utilizar para substituí-lo (nesse caso, "Abacate").
Conferindo que a alteração realmente foi feita:
$ cat lero_lero.txt
Abacate o modo pelo qual a adoção de políticas descentralizadoras talvez venha a ressaltar a relatividade de alternativas às soluções ortodoxas.
Adicionando etc...
$ git add lero_lero.txt
$ git commit -m "Modificando as três palavras iniciais para serem \"Abacate\""
[main f3fadb4] Modificando as três palavras iniciais para serem "Abacate"
1 file changed, 1 insertion(+), 1 deletion(-)
para se utilizar aspas dentro da mensagem de commit há de se escapar estas com uma barra invertida (
\)
No repositório remoto
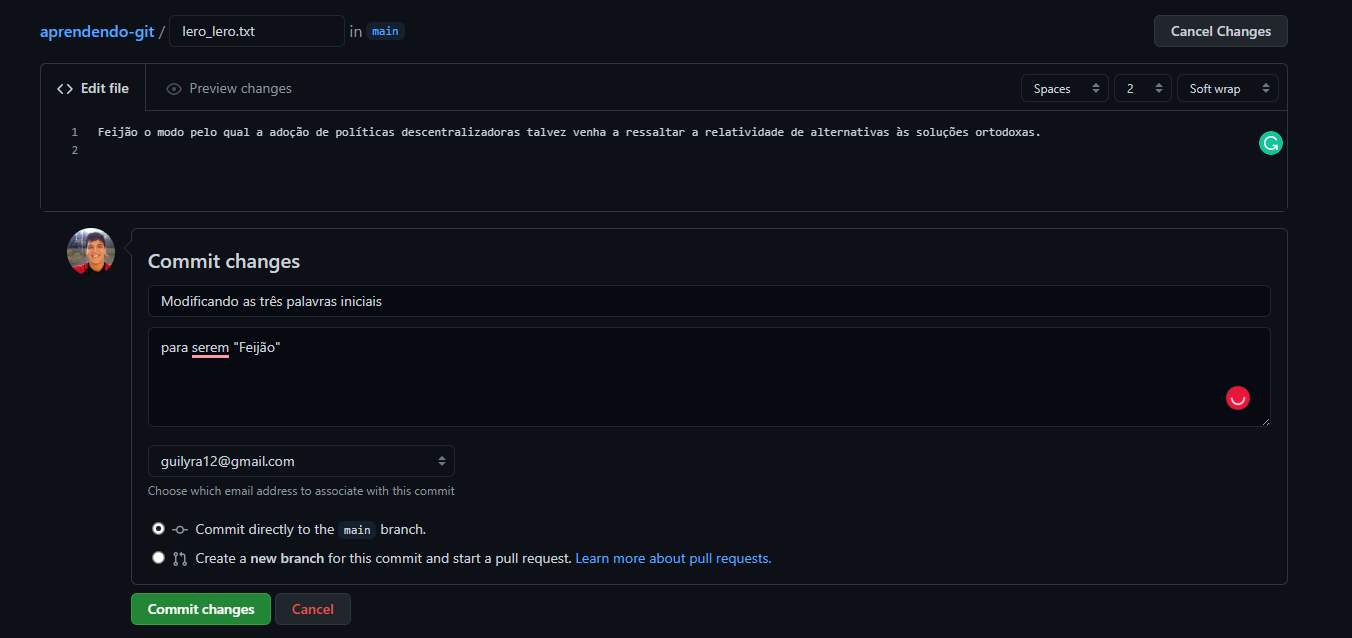
Resolvendo conflitos
Merge:
$ git pull
remote: Enumerating objects: 5, done.
remote: Counting objects: 100% (5/5), done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 3 (delta 1), reused 0 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), done.
From https://github.com/guilhermedelyra/aprendendo-git
8e756f1..9f31cb2 main -> origin/main
Auto-merging lero_lero.txt
CONFLICT (content): Merge conflict in lero_lero.txt
Automatic merge failed; fix conflicts and then commit the result.
$ cat lero_lero.txt
<<<<<<< HEAD
Abacate o modo pelo qual a adoção de políticas descentralizadoras talvez venha a ressaltar a relatividade de alternativas às soluções ortodoxas.
=======
Feijão o modo pelo qual a adoção de políticas descentralizadoras talvez venha a ressaltar a relatividade de alternativas às soluções ortodoxas.
>>>>>>> 9f31cb2472888021c5c6e398cdd6f9ffe358e99f
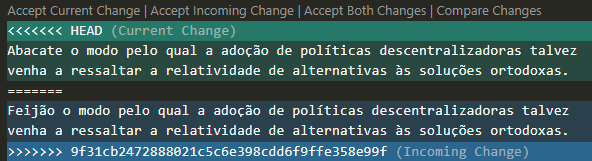
$ git status
On branch main
Your branch and 'origin/main' have diverged,
and have 1 and 1 different commits each, respectively.
(use "git pull" to merge the remote branch into yours)
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: lero_lero.txt
no changes added to commit (use "git add" and/or "git commit -a")
$ git checkout --ours lero_lero.txt
$ cat lero_lero.txt
Abacate o modo pelo qual a adoção de políticas descentralizadoras talvez venha a ressaltar a relatividade de alternativas às soluções ortodoxas.
$ git add lero_lero.txt
$ git status
On branch main
Your branch and 'origin/main' have diverged,
and have 1 and 1 different commits each, respectively.
(use "git pull" to merge the remote branch into yours)
All conflicts fixed but you are still merging.
(use "git commit" to conclude merge)
$ git commit --no-edit
[main dc59eb9] Merge branch 'main' of https://github.com/guilhermedelyra/aprendendo-git into main
$ git log --online
dc59eb9 (HEAD -> main) Merge branch 'main' of https://github.com/guilhermedelyra/aprendendo-git into main
9f31cb2 (origin/main) Modificando as três palavras iniciais
f3fadb4 Modificando as três palavras iniciais para serem "Abacate"
8e756f1 Merge remote-tracking branch 'origin/main' into main
17cb2da adicionando arquivo lero lero para enriquecer tutorial
fc0e748 Adicionando arquivo README
fc48527 Adicionando arquivo Lorem Ipsum de 1 paragrafo
Rebase:
$ git pull --rebase
remote: Enumerating objects: 5, done.
remote: Counting objects: 100% (5/5), done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 3 (delta 1), reused 0 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), done.
From https://github.com/guilhermedelyra/aprendendo-git
8e756f1..9f31cb2 main -> origin/main
First, rewinding head to replay your work on top of it...
Applying: Modificando as três palavras iniciais para serem "Abacate"
Using index info to reconstruct a base tree...
M lero_lero.txt
Falling back to patching base and 3-way merge...
Auto-merging lero_lero.txt
CONFLICT (content): Merge conflict in lero_lero.txt
error: Failed to merge in the changes.
Patch failed at 0001 Modificando as três palavras iniciais para serem "Abacate"
Use 'git am --show-current-patch' to see the failed patch
Resolve all conflicts manually, mark them as resolved with
"git add/rm <conflicted_files>", then run "git rebase --continue".
You can instead skip this commit: run "git rebase --skip".
To abort and get back to the state before "git rebase", run "git rebase --abort".
$ cat lero_lero.txt
<<<<<<< HEAD
Feijão o modo pelo qual a adoção de políticas descentralizadoras talvez venha a ressaltar a relatividade de alternativas às soluções ortodoxas.
=======
Abacate o modo pelo qual a adoção de políticas descentralizadoras talvez venha a ressaltar a relatividade de alternativas às soluções ortodoxas.
>>>>>>> Modificando as três palavras iniciais para serem "Abacate"
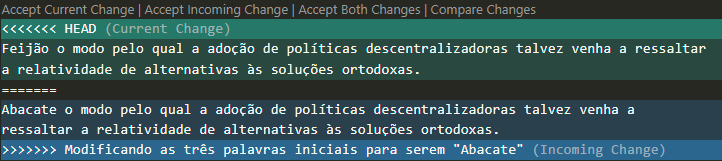
$ git status
rebase in progress; onto 9f31cb2
You are currently rebasing branch 'main' on '9f31cb2'.
(fix conflicts and then run "git rebase --continue")
(use "git rebase --skip" to skip this patch)
(use "git rebase --abort" to check out the original branch)
Unmerged paths:
(use "git reset HEAD <file>..." to unstage)
(use "git add <file>..." to mark resolution)
both modified: lero_lero.txt
no changes added to commit (use "git add" and/or "git commit -a")
$ git checkout --ours lero_lero.txt
$ cat lero_lero.txt
Feijão o modo pelo qual a adoção de políticas descentralizadoras talvez venha a ressaltar a relatividade de alternativas às soluções ortodoxas.
$ git add lero_lero.txt
$ git status
rebase in progress; onto 9f31cb2
You are currently rebasing branch 'main' on '9f31cb2'.
(all conflicts fixed: run "git rebase --continue")
nothing to commit, working tree clean
$ git rebase --continue
Applying: Modificando as três palavras iniciais para serem "Abacate"
No changes - did you forget to use 'git add'?
If there is nothing left to stage, chances are that something else
already introduced the same changes; you might want to skip this patch.
Resolve all conflicts manually, mark them as resolved with
"git add/rm <conflicted_files>", then run "git rebase --continue".
You can instead skip this commit: run "git rebase --skip".
To abort and get back to the state before "git rebase", run "git rebase --abort".
$ git rebase --skip
$ git status
On branch main
Your branch is up to date with 'origin/main'.
nothing to commit, working tree clean
$ git log --online
9f31cb2 (HEAD -> main, origin/main) Modificando as três palavras iniciais
8e756f1 Merge remote-tracking branch 'origin/main' into main
17cb2da adicionando arquivo lero lero para enriquecer tutorial
fc0e748 Adicionando arquivo README
fc48527 Adicionando arquivo Lorem Ipsum de 1 paragrafo
F.A.Q
Tempo estimado de leitura: 1min
As perguntas mais frequentes & votadas no Stackoverflow :^)
Ambientação
Tempo estimado de leitura: 1min
Nesse capítulo você aprenderá:
- Como funciona uma arquitetura cliente-servidor
- Projeto completo em Javascript
- O que é e como utilizar Docker
- Contribuindo com um repositório Open Source
Arquitetura Cliente-Servidor
Tempo estimado de leitura: 1min
De forma geral, principalmente se tratando de aplicações Web:
- Cliente = Front-end
- executado no computador do usuário
- responsável pelo "visual"
- Servidor = Back-end
- processos e serviços que são executados em um servidor dedicado (ou processos executados em background na máquina do usuário)
- responsável pela comunicação com banco de dados
Ok, mas como isso funciona? Quando você acessa um site, está acessando a aplicação "cliente" - que é responsável por estruturar os dados vindos do Servidor em um template visual.
Exemplo 1
(não real, apenas para ilustração)
- o Usuário acessa a aplicação-cliente no endereço https://www.blog.com
- a aplicação-cliente pede à aplicação-servidor os últimos 3 posts em https://www.api_do_blog.com/posts
-
aplicação-servidor acessa o banco de dados, que retorna todos os
Nposts já feitos, estruturados da forma:{ nome: "Nome do post", conteúdo: "Lorem ipsum dolor sit amet", data_de_publicação: "DD-MM-YYYY" } -
aplicação-servidor ordena esses dados pela data
-
aplicação-servidor retorna os 3 posts mais recentes para a aplicação-cliente
-
- aplicação-cliente estrutura os dados recebidos de uma forma visual:
<body> { for post in posts } <div> <p>{ post.nome }</p> <p>{ post.conteúdo }</p> <p>{ post.data_de_publicação }</p> </div> { end for} </body> - aplicação-cliente retorna
htmlfinal do endereço https://www.blog.com ao Usuário, que então é renderizado pelo navegador<body> <div> <p>Post A</p> <p>Conteudo do Post A</p> <p>25-03-2021</p> </div> <div> <p>Post B</p> <p>Conteudo do Post B</p> <p>24-03-2021</p> </div> <div> <p>Post C</p> <p>Conteudo do Post C</p> <p>21-03-2021</p> </div> </body>
Exemplo 2
(não real, apenas para ilustração)
- Usuário abre jogo Pokemon pelo aplicativo no celular
- Usuário toca no ícone de lista de pokemons
- aplicativo faz requisição para servidor em pokeapi.co/api/v2/pokemon
- servidor acessa banco de dados, retorna todos os pokemons, com
nome+url... - aplicativo mostra lista de pokemons
Projeto completo em Javascript
Tempo estimado de leitura: 5min
Este tutorial têm como objetivo:
- Elucidar melhor como funciona a arquitetura Cliente-Servidor
- Demonstrar como preparar o ambiente da sua máquina
- Demonstrar como funciona a estrutura de um projeto Javascript
- Conseguir fazer uma interação completa entre o front, back e banco
Se trata de uma aplicação de mundo real, baseada no Medium: https://demo.realworld.io/#/ Pode encontrar mais informações sobre esse projeto aqui.
| Projeto | Stack | Url do projeto |
|---|---|---|
| Backend | Node.js, Express, MongoDB | https://github.com/gothinkster/node-express-realworld-example-app |
| Frontend | React, Redux | https://github.com/gothinkster/react-redux-realworld-example-app |
Instalação
Clonar repositórios
$ mkdir conduit
$ cd conduit
$ git clone https://github.com/gothinkster/node-express-realworld-example-app backend
$ git clone https://github.com/gothinkster/react-redux-realworld-example-app frontend
Instalar MongoDB
MongoDB é um SGBD (Sistema Gerenciador de Banco de Dados) orientado a Documentos, sendo categorizado como NoSql.
$ wget -qO - https://www.mongodb.org/static/pgp/server-4.4.asc | sudo apt-key add -
$ echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu focal/mongodb-org/4.4 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.4.list
$ sudo apt update
$ sudo apt-get install -y mongodb-org
$ sudo systemctl start mongod
$ sudo systemctl status mongod
$ sudo mkdir -p /data/db
$ sudo chown -R `id -u` /data/db
$ mongod
Istalar NPM e Yarn
São gerenciadores de pacotes Javascript, portanto, utilizados para instalar bibliotecas externas.
npm= gerenciador padrãoyarn= surgiu com algumas otimizações em relação aonpm, sendo normalmente mais rápido
hoje em dia há quem argumente que ambos estão em pé de igualdade
$ sudo apt install nodejs npm
$ npm install --global yarn
Entendendo estrutura dos projetos
Felizmente, é bem simples de se abstrair o funcionamento de qualquer projeto JS: caso o README.md não providencie todas as informações necessárias, basta começar a ler pelo package.json :D
A partir da pasta conduit:
$ tree -L 2
.
├── backend
│ ├── app.js
│ ├── config
│ ├── models
│ ├── package.json
│ ├── project-logo.png
│ ├── public
│ ├── README.md
│ ├── routes
│ ├── tests
│ └── yarn.lock
└── frontend
├── package.json
├── project-logo.png
├── public
├── README.md
├── src
└── yarn.lock
9 directories, 9 files
Package.json
Antes de começarmos a ler de fato ambos os package.json, vamos ver a similaridade destes:
backend/package.json:
{
"name": "conduit-node",
"version": "1.0.0",
"description": "conduit on node",
"main": "app.js",
"scripts": {
"mongo:start": "docker run --name realworld-mongo -p 27017:27017 mongo & sleep 5",
"start": "node ./app.js",
"dev": "nodemon ./app.js",
"test": "newman run ./tests/api-tests.postman.json -e ./tests/env-api-tests.postman.json",
"stop": "lsof -ti :3000 | xargs kill",
"mongo:stop": "docker stop realworld-mongo && docker rm realworld-mongo"
},
"repository": {
"type": "git",
"url": "git+https://github.com/gothinkster/productionready-node-api.git"
},
"license": "ISC",
"dependencies": {
"body-parser": "1.15.0",
"cors": "2.7.1",
"ejs": "2.4.1",
"errorhandler": "1.4.3",
"express": "4.13.4",
"express-jwt": "3.3.0",
"express-session": "1.13.0",
"jsonwebtoken": "7.1.9",
"method-override": "2.3.5",
"methods": "1.1.2",
"mongoose": "4.4.10",
"mongoose-unique-validator": "1.0.2",
"morgan": "1.7.0",
"passport": "0.3.2",
"passport-local": "1.0.0",
"request": "2.69.0",
"slug": "0.9.1",
"underscore": "1.8.3"
},
"devDependencies": {
"newman": "^3.8.2",
"nodemon": "^1.11.0"
}
}
frontend/package.json:
{
"name": "react-redux-realworld-example-app",
"version": "0.1.0",
"private": true,
"devDependencies": {
"cross-env": "^5.1.4",
"react-scripts": "1.1.1"
},
"dependencies": {
"history": "^4.6.3",
"marked": "^0.3.6",
"prop-types": "^15.5.10",
"react": "^16.3.0",
"react-dom": "^16.3.0",
"react-redux": "^5.0.7",
"react-router": "^4.1.2",
"react-router-dom": "^4.1.2",
"react-router-redux": "^5.0.0-alpha.6",
"redux": "^3.6.0",
"redux-devtools-extension": "^2.13.2",
"redux-logger": "^3.0.1",
"superagent": "^3.8.2",
"superagent-promise": "^1.1.0"
},
"scripts": {
"start": "cross-env PORT=4100 react-scripts start",
"build": "react-scripts build",
"test": "cross-env PORT=4100 react-scripts test --env=jsdom",
"eject": "react-scripts eject"
}
}
Bom, fora o trivial (como name, version, description etc), o que salta aos olhos são: dependencies e scripts.
Scripts: são definidos pelo próprio desenvolvedor, sendo que podem ser até mesmo comandos que não utilizam alguma bibliotecaJS. Por exemplo, poderiamos adicionar a chave"list": "ls"dentro de"scripts", e rodar o comando comnpm run listouyarn run list, que teria como output a listagem do diretório do repositório atual.
Obs: na maioria das vezes não é necessário incluir
runno uso do yarn (ex:yarn buildem vez deyarn run build); neste caso há de se incluir orunpoislisté um comando padrão doyarnutilizado para listar todos os pacotes instalados neste projeto (incluindo dependencias das dependencias etc)
Dependencies: como o próprio nome da a entender, são as dependencias utilizadas naquele projeto. É sempre interessante/importante que você tenha ao menos uma noção do que as libs incluídas fazem... Basta acessar https://www.npmjs.com/package/ e incluir no final da url o pacote que está "inspecionando"; por exemplo: https://www.npmjs.com/package/marked
Você pode encontrar mais informações sobre o package.json aqui.
Instalando dependencias dos projetos
Antes de executarmos cada um dos projetos, precisamos instalar as dependencias previamente citadas: Abra dois terminais distintos (ou dê "split" caso seu terminal tenha essa opção), que serão referenciados aqui no tutorial como T1 e T2.
Segue, então, o passo-a-passo a ser realizado em cada um dos terminais:
Ambos a partir da pasta conduit
|
Comandos no T1 |
Comandos no T2 |
|
|
|
|
|
|
|
Url: localhost:3000 |
Url: localhost:4100 |
yarné o mesmonpm installyarn starté o mesmo quenpm run startyarn devé o mesmo quenpm run dev
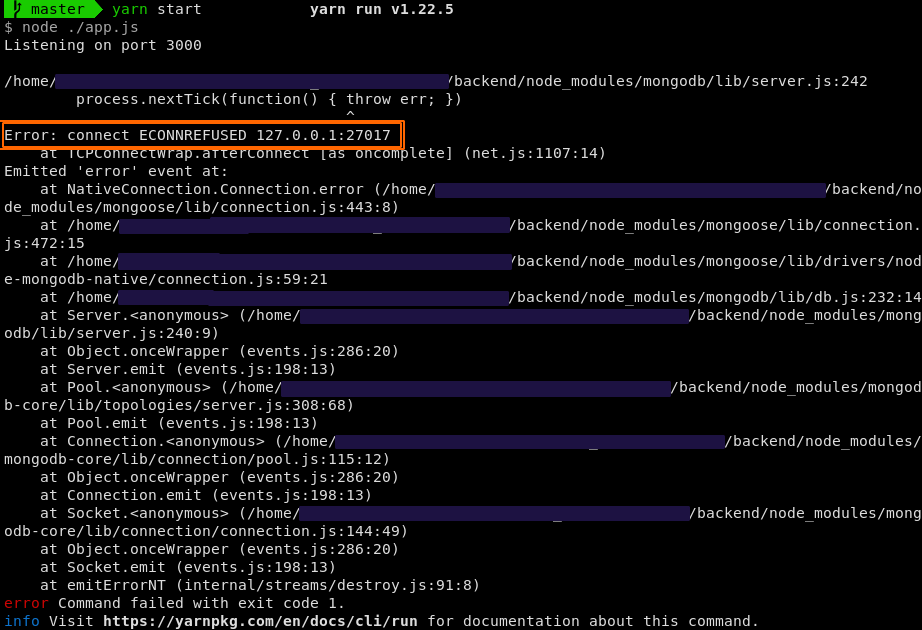
Caso apareça um erro de conexão ao subir o serviço do backend como o mostrado abaixo, provavelmente acontecera por conta do serviço
mongodnão ter sido inicializado; para tanto, basta executar:$ sudo systemctl start mongod* obs: pode executar o mesmo comando acima substituindo
startporenablepara inicializar o serviço junto com o sistema operacional.Mongod error
Agora, com ambos os serviços funcionando, você pode interagir com seu site localmente :D
Por ora é isso :) Veja os próximos capítulos para compreender melhor o funcionamento do Backend & Frontend.
Backend
Tempo estimado de leitura: 1min
Para interagir com o backend, em geral, é mais indicado utilizar Postman ou Insomnia
Ambas as ferramentas são utilizadas para fazer requisições http; dessa forma, para testar alguma rota especifica do backend, não será necessário, por exemplo, navegar nas telas do frontend até chegar no botão X que faz uma requisição especifica em alguma rota do backend.
Não é necessário, também, ir ao mais "baixo nível" que seria utilizando o comando curl e afins.
Exemplificando:
-
Crie um novo request no Postman
-
Preencha as informações:
url = http://localhost:3000/api/users/
tipo = POST
body = raw, json
{
"user": {
"email": "john@jacob.com",
"password": "johnnyjacob",
"username": "johnjacob"
}
}
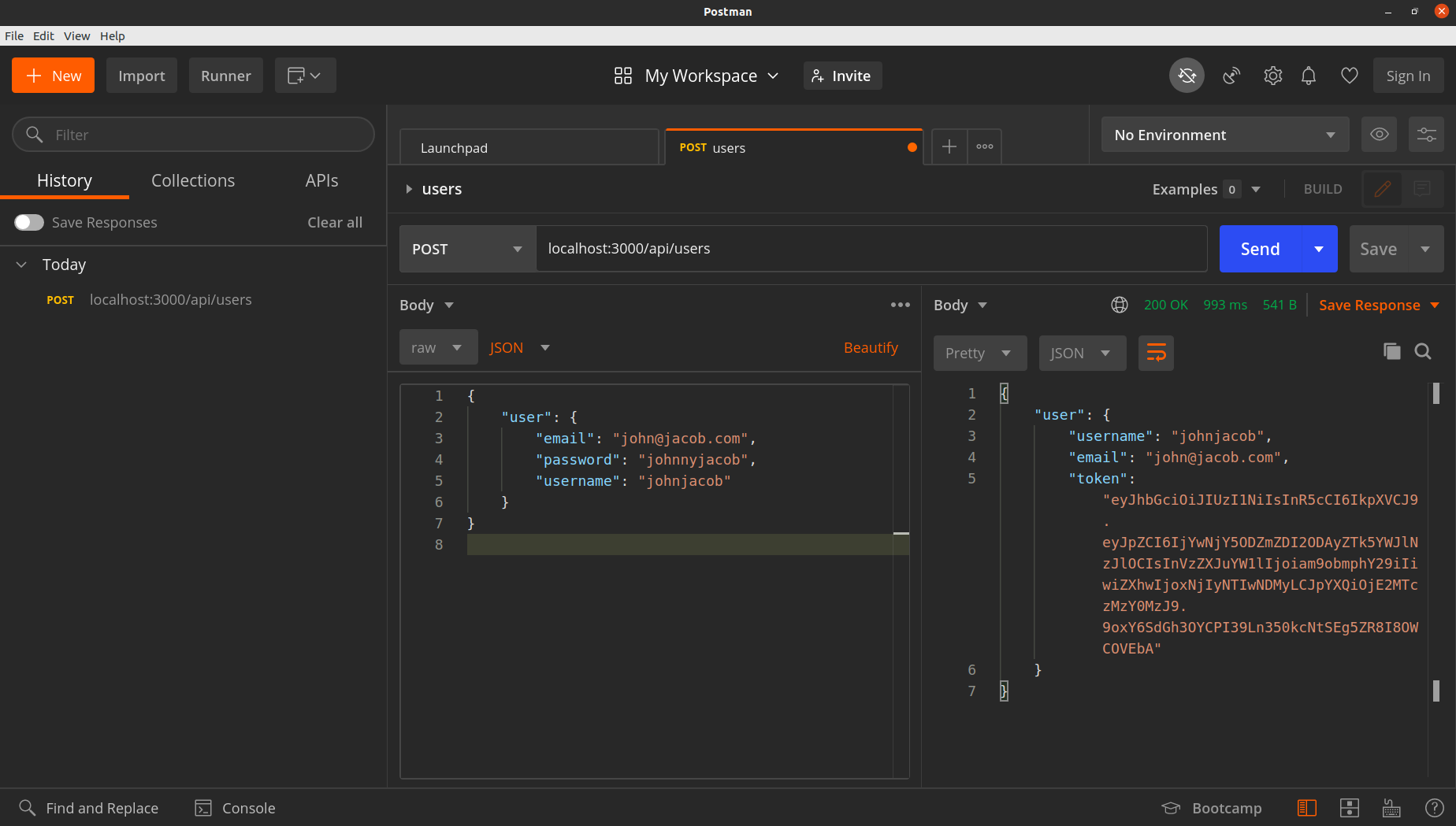
Para entender melhor esse request, vamos verificar como está especificada a criação de usuários no backend.
Abra backend/routes/api/users.js(L63-73):
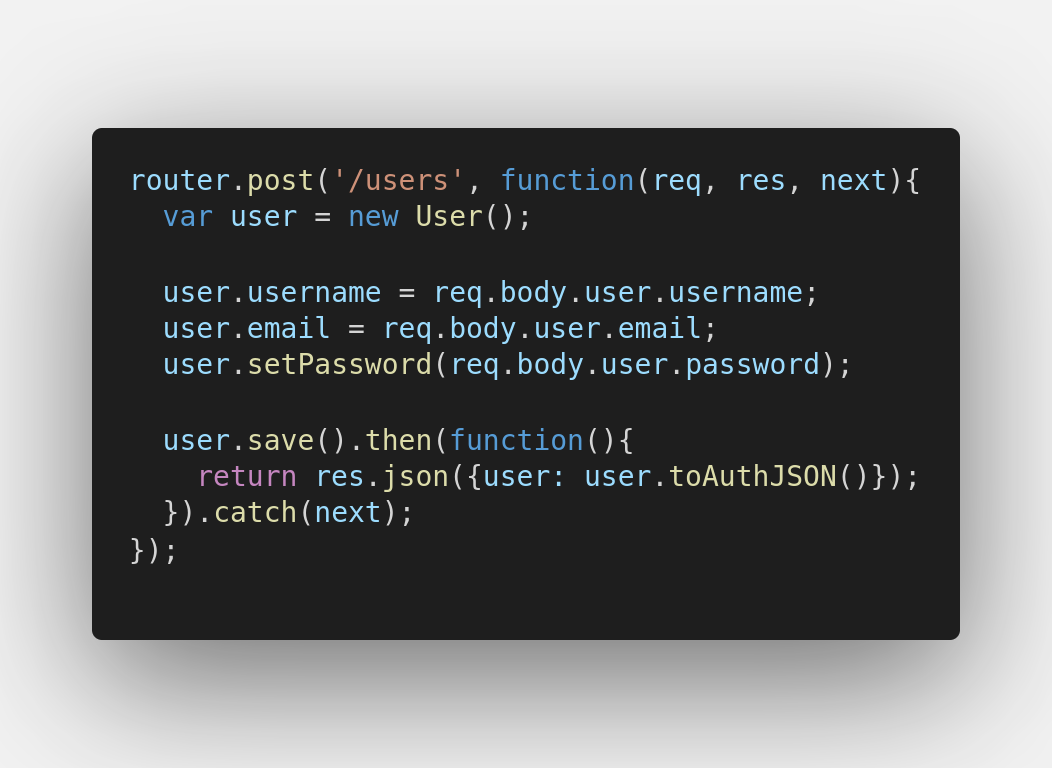
Perceba que user é uma instância da model User:
Em backend/routes/api/users.js(L4)

Para entendermos o que é essa model,
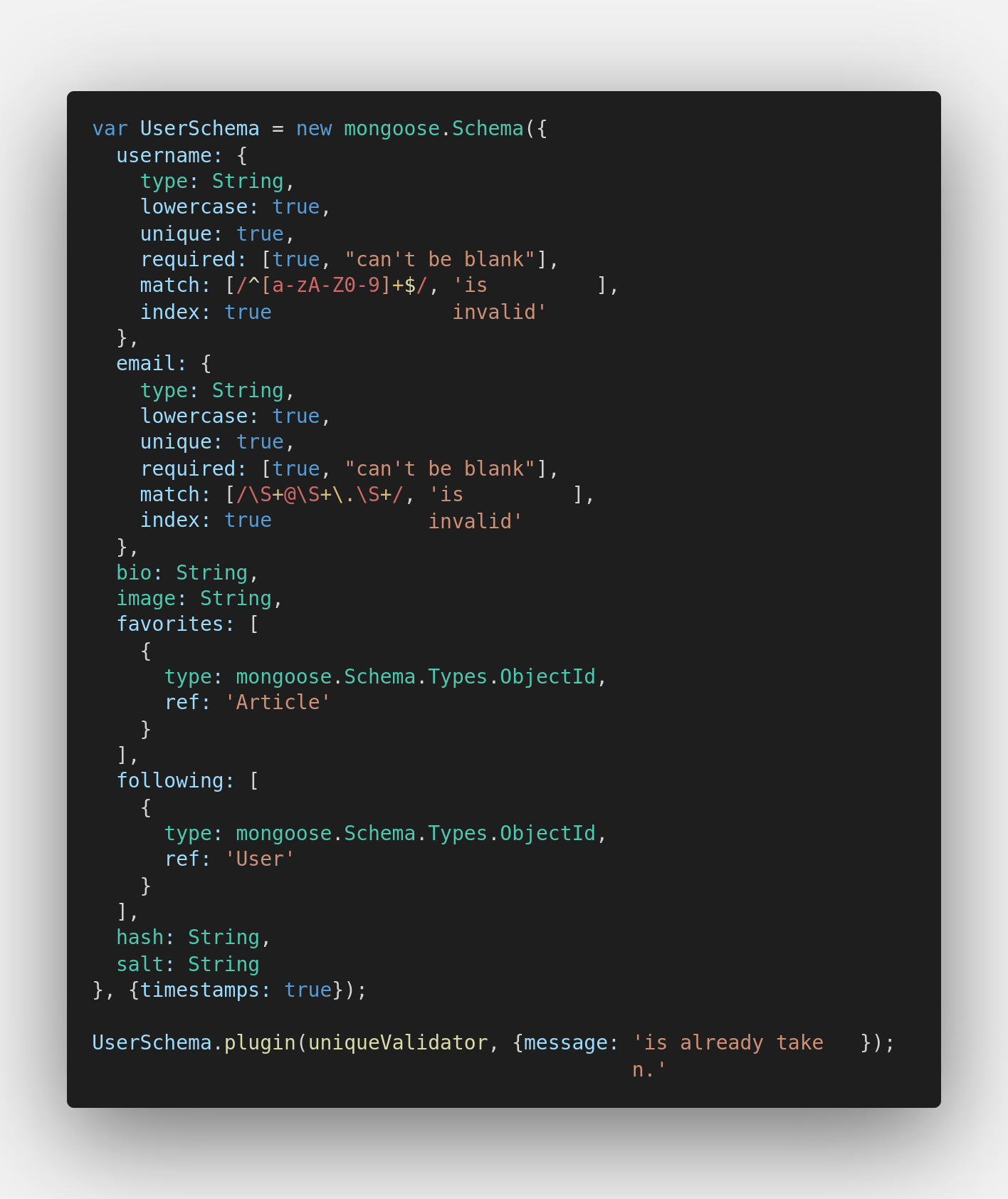
Abra backend/models/Users.js:
Não precisamos nos aprofundar muito, mas, de acordo com o código visto acima, há 3 trechos relevantes:
Schema:
Set Password:
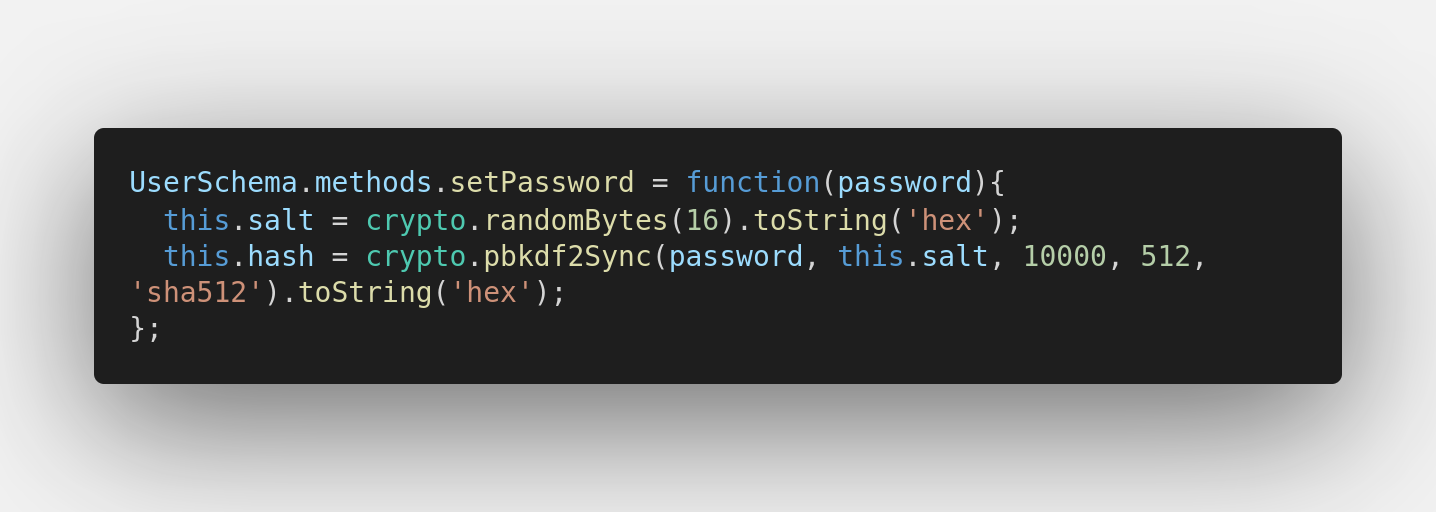
é recomendada a pesquisa sobre
pbkdf2,bcrypt,sha512,salt,pepperno contexto de criptografia :) mas, basicamente trata-se de uma segurança a mais para armazenar as senhas dos usuários dificultando que hackers consigam "adivinhar" a senha dos usuários (seja através de bruteforce ou de "ataques rainbow table")
To Auth Json:
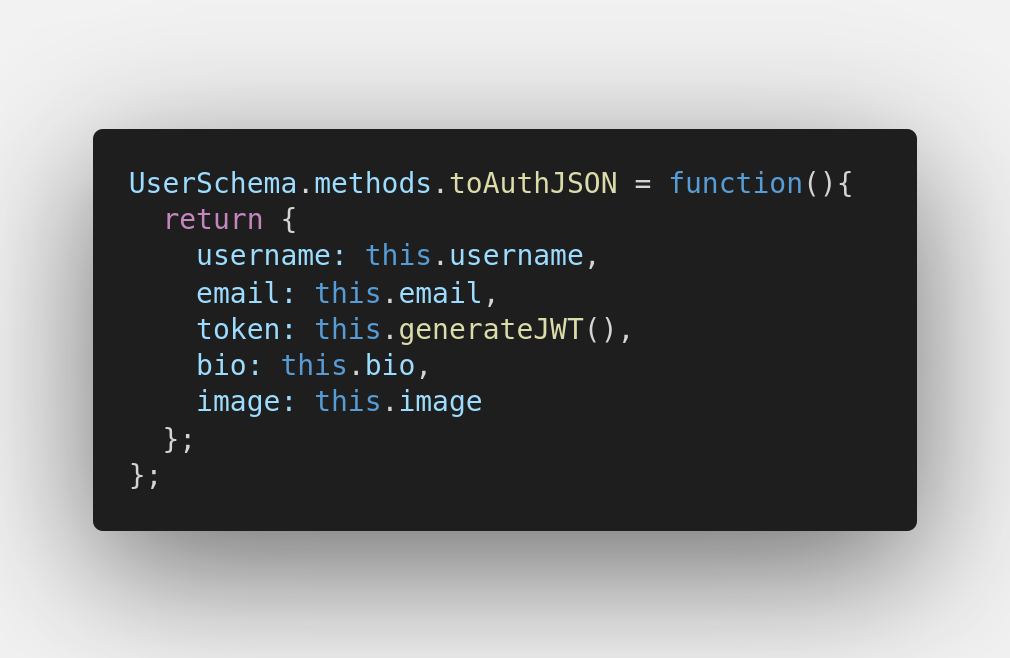
Com isso tudo, podemos inferir bastante sobre o funcionamento do request que fizemos:
A api recebe nosso request (incluindo o corpo de texto [em formato json] com informações de cadastro do usuário), valida se o username, email e password atendem as especificações do Schema (por ex: não podemos cadastrar "abc" como email), a senha é criptografada e, então, o usuário é salvo no banco de dados Mongo;
Caso tudo tenha ocorrido corretamente, o servidor responde o request do usuário mostrando informações básicas de como o usuário foi cadastrado no banco de dados.
Frontend
Tempo estimado de leitura: 1min
Primeiramente, vamos modificar uma linha de código:
Vá até conduit/frontend/src/agent.js(L6) e substitua a url:
De:
const API_ROOT = 'https://conduit.productionready.io/api';
Para:
const API_ROOT = 'http://localhost:3000/api';
Dessa forma, garantimos que a aplicação esteja comunicando com nossa api (e banco) locais.
Verificando Login
Caso você tenha realizado os passos do capítulo anterior, o usuário ja foi criado; portanto, basta acessar a página de login:
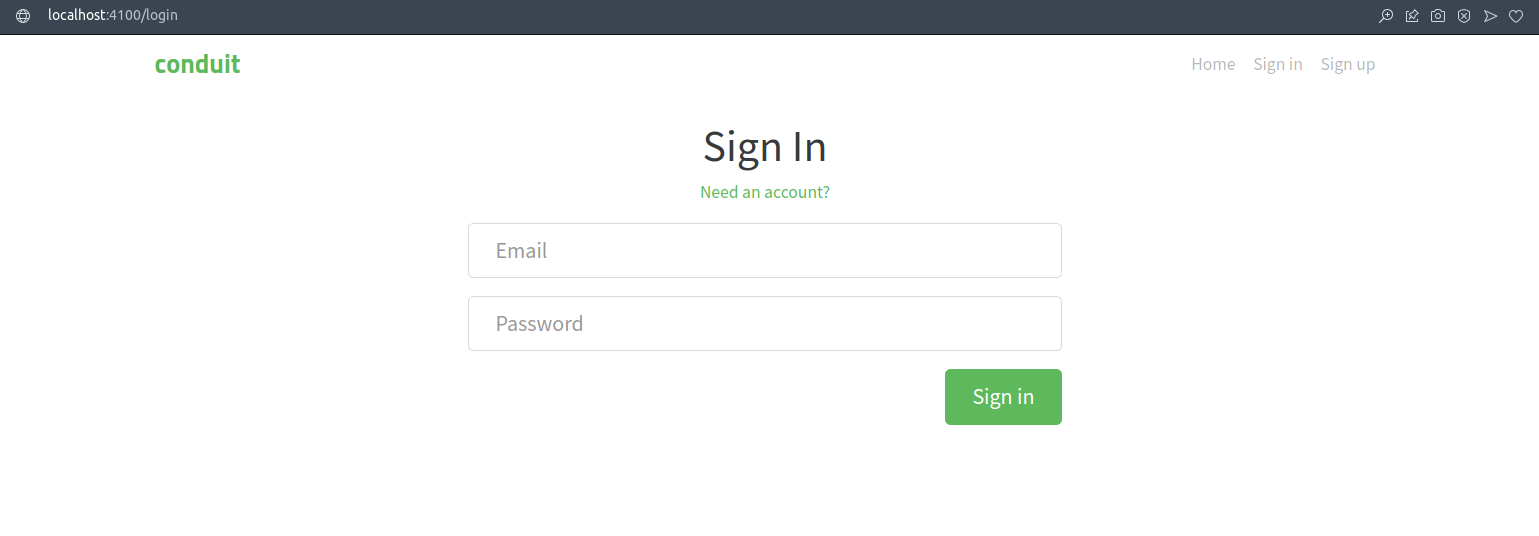
E inserir as credenciais
email: john@jacob.com
password: johnnyjacob
Você deve ser redirecionado para pagina inicial:

Resumão Docker
Tempo estimado de leitura: 4min
Disclaimer: esse capítulo (de introdução) é 100% baseado nesse vídeo ->

Problema
Suponha que voce está desenvolvendo um app em Cobol, que roda numa plataforma Linux aleatória (ex: archlinux), e você deseja compartilhar esse app com seu amigo; entretanto, ele utiliza um sistema totalmente diferente (ex: debian, windows 7, etc)...
Então, surge a questão:
Como replicar esse ambiente que meu app precisa em qualquer computador?
Máquinas Virtuais
Uma das soluções possíveis é utilizar uma Virtual Machine (e existem varias opções para isso, como: VirtualBox, Vmware, GnomeBoxes, Qemu, dentre outros)
O que são máquinas virtuais? São computadores completos: possuem CPU, memória RAM, disco rigido, sistema operacional, arquivos, aplicativos... tudo. Mas, tudo isso é virtual/simulado, utilizando recursos do computador físico/servidor "real" -- também conhecido como Host.
Então, a idéia seria: um simulador de computador que será configurado de forma igual (idealmente) pelos devs do projeto, utilizando um mesmo sistema operacional e instalando as dependencias necessárias pro projeto.
exemplo: todos instalam uma VM usando Manjaro, instalam os pacotes g++, libncurses etc (qualquer app/dependencia necessária pra rodar aquele projeto)
Mas... isso não é muito escalável quando se considera uma organização com múltiplos apps sendo desenvolvidos simultaneamente, por exemplo. Como as VMs tendem a ser pesadas (tanto em consumo de recursos computacionais do computador [real], como na performance individual), essa opção se torna meio inviável
Docker ao resgate
obs: existem outras opções surgindo atualmente, como o Podman (da Redhat); mas, no geral, container = Docker
Um Container de Docker é conceitualmente muito similar a uma VM, com uma distinção chave: em vez de virtualizar o Hardware (um computador inteiro), os Containers virtualizam apenas o S.O.; ou seja, todos os apps (ou, Containers) são executados por um único Kernel
É isso que torna a utilização de Docker tão mais rápida, flúida e eficiente.
Estrutura básica do Docker
Existem 3 pilares que constituem o universo de Docker:

Dockerfile
Este arquivo é como o DNA: um código que especifica ao Docker como ele deve buildar uma imagem.
Imagem
A imagem é um snapshot da sua aplicação: contém desde as dependencias do seu projeto (ex: pacotes npm etc) até o "sistema operacional". Vale ressaltar que essa imagem é imutavel, e pode ser utilizada para construir múltiplos containers.
Container
É a instancia em execução, criada a partir da imagem.
fazendo um paralelo com OO: img = classe; container = objeto [instancia da classe]
Exemplo Mínimo
Não é necessário reproduzir esses comandos, já que praticaremos isso junto no segundo sub-capítulo.
A partir desse Dockerfile de exemplo:

FROM ubuntu:20.04
Como um "import"; é uma imagem pré-definida que será utilizada como base nesse arquivo. Essa imagem é "puxada" do docker hub; essa imagem em específico se refere a este Dockerfile.
Existem N imagens pré-definidas, que podem ser utilizadas de acordo com a necessidade do seu projeto. Por exemplo: Python, Ruby, Node, dentre outras infinitas possibilidades.
Normalmente, quando há de se partir de uma imagem de um S.O. mais básico (como esse caso do exemplo), há uma certa preferência para a distribuição Alpine em vez de Ubuntu, por exemplo, por se tratar de uma distribuição mais minimalista.
RUN apt-get update -y && apt-get install -y tree
Com o comando
RUNvocê pode utilizar basicamente qualquer comando bash; nesse caso, estamos instalando o pacotetree(basicamente umlsque verifica as subpastas).
RUN mkdir -p test/nested && \
cd test && \
touch nested/a.txt b.txt
Para verificar o comando
treeem ação, dentro dessa imagem, a partir do endereço base/, criamos uma pasta aleatoria e outra subpasta; entramos* na pasta criada, e criamos dois arquivos.
RUN echo "current path: `pwd`"
RUN ls --format=across
RUN tree test/
Mesmo utilizando o comando
cdna linha passada, ao utilizarmos os comandospwdelsverificamos que retornamos ao endereço base; isso porque cada comandoRUNé executado a partir doWORKDIRatual.
CMD ["echo", "Hello World!"]
O comando
CMDdistingue-se doRUNpor se tratar de um comando que sera rodado ao executarmos um container; ou seja, no processo de build da imagem, este comando não é executado.
Então, ao executarmos o comando de build:
$ docker build -t exemplo_minimo .
A flag
-tserve pra especificar o nome da imagem que será construída


Após isso, podemos finalmente executar essa imagem (iniciando um container):

Observação:
A linha de criação de pastas etc poderia ser reescrita da seguinte forma:
WORKDIR test
RUN mkdir nested
RUN touch nested/a.txt b.txt
O comando
WORKDIRfunciona como ummkdir(se necessário) +cd(modificando o contexto ao longo de toda a imagem)
Entao, o comandotreepoderia ser utilizado no contexto atual., já que oWORKDIRdessa imagem não é mais o caminho base/, e, sim, o caminho/test/
Construindo um container mínimo
Tempo estimado de leitura: 11min
Para a construção desse container, precisaremos, basicamente, de 4 coisas:
-
chroot: significa change root. traz isolamento pro nosso container; ao utilizar isso, cria-se um novo processo que têm o root aparente modificado. Ou seja, dentro desse novo root, voce é incapaz de modificar os arquivos do root original. -
namespace: feature do kernel Linux que traz isolamento; basicamente, um container não consegue visualizar/manipular recursos de outros containers (ou do próprio host) [o host também não consegue visualizar os recursos/processos dentro dos containers]- controla o que voce pode ver/fazer
-
cgroup: significa control group. traz o controle de recursos; basicamente, voce pode especificar quanto de RAM, CPU etc aquele container poderá utilizar (de outra forma, ele tem acesso ilimitado aos recursos do host*)- controla o que voce pode usar
-
overlay: um dos sistemas de arquivos utilizados no kernel*. traz a integridade da imagem. ou seja, permite criar uma imagem limpa que será utilizada como base pra construção de containers. dessa forma, vc pode manipular os conteudos dos containers (adicionar libs arquivos, etc), mas isso não modificará a imagem original*existem inumeros tipos de filesystems (sistemas de arquivos); para listar os disponiveis no seu computador, rode o comando
cat /proc/filesystemsexemplo de alguns:
rootfs: o core de um sistema linux. contém todas as aplicações, configurações, dispositivos etc necessários para rodar seu sistema Linux
procfs: um pseudo-filesystem que provê uma interface de comunicação entre o kernel e o usuario (é utilizado por exemplo pelo "gerenciador de tarefas" [system monitor] para visualizar os recursos atuais do pc etc)
ext2-4: o sistema de arquivos utilizado por sistemas Unix; lida com conceitos de blocos, inodes, diretorios etc
Resumo dos comandos
Essa seção serve como um "cheatsheet" para recapitular quais comandos executar etc; caso seja a primeira vez lendo esse capitulo, pode passar para a proxima parte =)
Criando imagem do container (dentro da VM já):
mkdir container_minimo && cd "$_"
mkdir -p {,usr/}{{,s}bin,lib{,64}}
wget https://www.busybox.net/downloads/binaries/1.31.0-defconfig-multiarch-musl/busybox-i686 -O bin/busybox
chmod +x bin/busybox
chroot . /bin/busybox --install -s
cp /bin/bash bin/
cp /lib/x86_64-linux-gnu/libtinfo.so.6 /lib/x86_64-linux-gnu/libdl.so.2 /lib/x86_64-linux-gnu/libc.so.6 lib/
cp /lib64/ld-linux-x86-64.so.2 lib64/
cd
Criando o script make_container.sh:
echo $'#!/bin/bash
IMAGE_PATH=$1
for ARGUMENT in "$@"
do
KEY=$(echo $ARGUMENT | cut -f1 -d=)
VALUE=$(echo $ARGUMENT | cut -f2 -d=)
case "$KEY" in
CPU) CPU=${VALUE} ;;
RAM) RAM=${VALUE} ;;
*)
esac
done
function createRandomContainerName()
{
local prefix=$(</dev/urandom tr -dc a-z | head -c 1)
local randomName=$(</dev/urandom tr -dc a-z0-9_ | head -c 12)
echo "$prefix$randomName"
}
containerName=$(createRandomContainerName)
export containerName
function prepareFoldersForOverlayFS() {
mkdir -p /tmp/$containerName/{upper,workdir,overlay}
}
function createOverlayFS()
{
mount -t \
overlay -o lowerdir=$IMAGE_PATH,upperdir=/tmp/$containerName/upper,workdir=/tmp/$containerName/workdir \
none \
/tmp/$containerName/overlay
}
function installBusybox() {
chroot /tmp/$containerName/overlay/ /bin/busybox --install -s
}
function createCGroup() {
sleep 1
PID=$(ps aux | grep unshare | tail -2 | head -1 | awk \'{print $2}\')
cgcreate -a $containerName -g cpu,memory:$containerName
set -x
echo 5MB > /sys/fs/cgroup/memory/$containerName/memory.limit_in_bytes
echo 100 > /sys/fs/cgroup/cpu/$containerName/cpu.shares
# cgexec -g cpu,memory:$containerName $PID
cgclassify -g cpu,memory:$containerName $PID
set +x
# Limit usage at 5% for a multi core system
# cgset -r cpu.cfs_period_us=100 -r cpu.cfs_quota_us=$[ 5000 * $(getconf _NPROCESSORS_ONLN) ] $containerName
# Set a limit of 80M
# cgset -r memory.limit_in_bytes=80M $containerName
}
function setUpContainer() {
export PS1="$containerName-# ";
mkdir proc;
mount -t proc none proc;
bash
}
export -f setUpContainer
function launchContainer() {
unshare --mount --uts --ipc --net --pid --fork --user --map-root-user \
chroot /tmp/$containerName/overlay \
bash -c "setUpContainer"
}
export -f launchContainer
function makeContainer() {
set -x
sudo -u $containerName bash -c "launchContainer"
set +x
}
prepareFoldersForOverlayFS
createOverlayFS
installBusybox
adduser --disabled-password --gecos "" $containerName
usermod -aG sudo $containerName
printf "\n$containerName ALL=(ALL) NOPASSWD: /usr/sbin/chroot, /usr/bin/unshare\n" >> /etc/sudoers
createCGroup &
makeContainer
' > make_container.sh
Instalando uma máquina virtual para rodar esse tutorial
Para evitar poluir seu sistema operacional com esse tutorial, fazer testes livremente, vamos instalar uma VM (extremamente leve) para servir de sandbox:
| # | Passo | Comando |
|---|---|---|
| 1 | Instalar VirtualBox | Abra o link e selecione o metodo de sua preferencia: https://www.virtualbox.org/wiki/Linux_Downloads |
| 2 | Instalar bakerX (front-end for creating and managing (micro) virtual environments) | Opção 1: npm install ottomatica/bakerx -gOpção 2: acesse o link |
| 3 | Baixar iso do ubuntu | bakerx pull focal cloud-images.ubuntu.com |
| 4 | Criar a VM | bakerx run construindo_container_minimo focal |
| 5 | Entrar na VM | bakerx ssh construindo_container_minimo |
| 6 | Garantir que sempre entraremos nessa VM como root | printf "sudo -i\n" >> ~/.bashrc && exec $SHELL |
| 6 | Dar update p instalar alguns utilitarios | apt update |
| 7 | Instalar:tree (listar diretorios e subdiretorios) | apt install tree |
Atenção
Caso o terminal esteja tendo comportamento inesperado (ex: ao apertar Backspace, surge um espaço), talvez tenha que modificar o $TERM
# no seu pc mesmo, no host
~# echo $TERM
xterm-kitty
# na VM {que acessa com o bakerx}
~# echo "export TERM=xterm" >> ~/.bashrc
~# exec $SHELL
Preparando um diretorio para ser nosso container
Ainda dentro de nossa VM (passo 5):
Vamos criar algumas pastas replicando o filesystem do Linux:
Obs: omitirei o nome
root@ubuntu-focal:~#aqui para poluir menos
Ou seja, no seu terminal você verá
root@ubuntu-focal:~#, aqui no tutorial apenas~#
~# mkdir container_minimo && cd "$_"
~/container_minimo# mkdir -p {,usr/}{{,s}bin,lib{,64}}
A estrutura atual da pasta deve estar assim:
~/container_minimo# tree
.
├── bin
├── lib
├── lib64
├── sbin
└── usr
├── bin
├── lib
├── lib64
└── sbin
7 directories, 0 files
Vamos adicionar um pacote para utilizarmos dentro desse container que estamos criando?
Copie o pacote ls para a pasta atual:
~/container_minimo# cp /bin/ls bin/ls
Vamos rodar o comando ls dentro do nosso novo container (utilizando o comando chroot):
~/container_minimo# chroot . ls
chroot: can't execute 'ls': No such file or directory
Hmm... O problema é que esse comando (ls) necessita de algumas bibliotecas para funcionar. Felizmente, o comando ldd nos lista todas as dependencias que esse pacote possa ter:
~/container_minimo# ldd /bin/ls
/lib/ld-musl-x86_64.so.1 (0x7f951dcf1000)
libc.musl-x86_64.so.1 => /lib/ld-musl-x86_64.so.1 (0x7f951dcf1000)
Agora, basta copiar essa biblioteca para nosso container:
~/container_minimo# cp /lib/ld-musl-x86_64.so.1 lib/.
Agora, vamos tentar novamente rodar ls:
~/container_minimo# chroot . ls /
bin lib sbin usr
Funcionou :)
Vamos adicionar o bash também:
~/container_minimo# cp /bin/bash bin/
~/container_minimo# cp /lib/x86_64-linux-gnu/libtinfo.so.6 /lib/x86_64-linux-gnu/libdl.so.2 /lib/x86_64-linux-gnu/libc.so.6 lib/
~/container_minimo# cp /lib64/ld-linux-x86-64.so.2 lib64/
Entretanto, seria muito tedioso e exaustivo copiar cada comando que julgassemos necessarios (como, por exemplo, o shell bash, o comando cp, mv e assim por diante)
Portanto, vamos utilizar o Busybox (= varios comandos unix uteis, como cd, alias, mv etc)
~/container_minimo# wget https://www.busybox.net/downloads/binaries/1.31.0-defconfig-multiarch-musl/busybox-i686 -O bin/busybox
Torne esse arquivo em executavel
~/container_minimo# chmod +x bin/busybox
Instale os symlinks dentro do container:
~/container_minimo# chroot . /bin/busybox --install -s
Verifique que agora existem inumeros pacotes dentro da pasta de binarios:
~/container_minimo# chroot . ls /bin/
Interagindo com nosso container
Para entrarmos nesse nosso novo container (e utilizar o shell dentro do mesmo), basta rodar o comando bash:
~/container_minimo# PS1="C-$ " chroot . bash
o
PS1modifica o prompt; é so para distinguirmos o nome do shell dentro do container em relação ao mundo externo :)
Vamos criar um arquivo aleatorio dentro desse container:
C-$ touch teste.txt
C-$ ls
bin lib linuxrc sbin teste.txt usr
C-$ exit
Agora que saímos do container (com o exit), podemos ver um problema. A modificação que fizemos dentro do container veio para o "mundo real"...
~/container_minimo# ls
bin lib linuxrc sbin teste.txt usr
Aprimorando nosso container
Overlay
Para mantermos a integridade, vamos utilizar o overlayFS. Esse sistema consiste de 3 camadas:
- Lower: read-only, a imagem (não modificavel dentro do container) utilizada como base pra criação do container
- Upper: read-write, onde será armazenado as modificações feitas
- Overlay: o container de fato. a composição das duas camadas
existe ainda o
workdir. mas ele não têm tanto valor semantico, é so um diretorio aleatorio utilizado pelo kernel enquanto ele monta o Overlay

Como bônus, vamos montar o filesystem proc, também, para monitorarmos os recursos dentro desse container.
Crie um novo arquivo dentro da VM (não container) chamado make_container.sh (e vamos sair dessa pasta do container, também):
~/container_minimo# cd
~# vim make_container.sh
Aperte i para entrar no modo inserção dentro do editor de texto vim, copie o codigo abaixo e cole (ctrl + shift + v)
#!/bin/bash
CONTAINER_PATH=$1
function createRandomContainerName()
{
local randomName=$(</dev/urandom tr -dc A-Za-z0-9-_ | head -c 10)
echo "$randomName"
}
containerName=$(createRandomContainerName)
function prepareFoldersForOverlayFS()
{
mkdir -p /tmp/$containerName/upper \
/tmp/$containerName/workdir \
/tmp/$containerName/overlay
}
function createOverlayFS()
{
mount -t \
overlay -o lowerdir=$CONTAINER_PATH,upperdir=/tmp/$containerName/upper,workdir=/tmp/$containerName/workdir \
none \
/tmp/$containerName/overlay
}
function installBusybox() {
chroot /tmp/$containerName/overlay/ /bin/busybox --install -s
}
function launchContainer() {
PS1="$containerName-# " \
chroot /tmp/$containerName/overlay \
bash -c "mkdir /proc;
mount -t proc none /proc;
bash"
}
prepareFoldersForOverlayFS
createOverlayFS
installBusyLogarbox
launchContainer
Salve o arquivo (aperte ESC, digite :wq e aperte ENTER)
Vulnerabilidade: visualizando recursos que não deveria
Para visualizarmos melhor o motivo de precisarmos de namespaces, façamos o seguinte:
Inicie um container no background (adicionando & ao final do comando):
~# bash make_container.sh container_minimo/ &
Vamos verificar qual o PID (process id) do mesmo:
~# ps aux | grep make_container.sh
1327 root 0:00 bash make_container.sh container_minimo/
1445 root 0:00 grep make_container.sh
Mas, quando se inicia um processo no background (utilizando o operador &), podemos verificar o PID deste processo de forma mais simples:
~# echo $!
1327
Ok, sabemos agora que o PID desse container rodando no background é 1327.
Logar
Vamos verificar quais processos são possiveis de ser visualizados dentro desse container:
qqyioEo0gM-# ps
...
1097 0 0:00 sshd: root@pts/0
1099 0 0:00 -ash
1326 0 0:00 [kworker/u2:1-ev]
1327 0 0:00 bash make_container.sh container_minimo/
1337 0 0:00 bash
1412 0 0:00 bash make_container.sh container_minimo/
1422 0 0:00 bash
1427 0 0:00 ps
Opa! Eu consigo visualizar o PID do outro container, o que é uma vulnerabilidade bem grande. Com isso, eu poderia encerrar o outro container facilmente:
qqyioEo0gM-# kill -9 1327
Saindo do container atual, vamos verificar se o container que estava em background ainda está em execução:
qqyioEo0gM-# exit
~# ps aux | grep make_container.sh
1447 root 0:00 grep make_container.sh
Logaro Namespace. De acordo com a Wikipedia:
Namespaces are a feature of the Linux kernel that partitions kernel resources such that one set of processes sees one set of resources while another set of processes sees a different set of resources. The feature works by having the same namespace for a set of resources and processes, but those namespaces refer to distinct resources. Resources may exist in multiple spaces. Examples of such resources are process IDs, hostnames, user IDs, file names, and some names associated with network access, and interprocess communication.
. . .
Three syscalls can directly manipulate namespaces:
clone, flags to specify which new namespace the new process should be migrated to.
unshare, allows a process (or thread) to disassociate parts of its execution context that are currently being shared with other processes (or threads)
setns, enters the namespace specified by a file descriptor.
Para o nosso caso, utilizaremos o comando unshare.
Modifique a função launchContainer() dentro do arquivo make_container.sh da seguinte forma:
function launchContainer() {
PS1="$containerName-# " \
unshare --mount --uts --ipc --net --pid --fork --user --map-root-user \
chroot /tmp/$containerName/overlay \
bash -c "mkdir /proc;
mount -t proc none /proc;
bash"
}
existe uma flag do
unshareque já monta o procfs para nós (--mount-proc), o que significa que bastaria instanciar o shell (sem necessidade de rodar a flag-ce os respectivos comandos criando & montando o procfs)
Vamos instanciar um processo aleatorio em background novamente:
~# sleep 6000 &
Verificando qual o PID do mesmo:
~# echo $!
1107
Agora, vamos entrar num container e tentar encerrar esse processo:
uaLxGqwWPW-# kill -9 1107
bash: can't kill pid 1107: No such process
Epa! Vamos verificar quais processos podemos enxergar:
uaLxGqwWPW-# ps
PID USER TIME COMMAND
1 0 0:00 bash
4 0 0:00 ps
Pronto! Criamos um novo namespace isolado do host :D
CGroups
Bem, a ultima questão é o fato de que nosso container tem acesso irrestrito ao uso de recursos computacionais do host.
Significa que pode usar quanta cpu, ram etc precisar
Isso é um problema pois, imagine o seguite cenario:
voce tem um servidor com 500tb de armazenamento, 512gb de ram, cpu brabo etc
e ai decide alugar esse servidor da seguinte forma:
qualquer pessoa manda o container da aplicação que tem, e esse servidor vai rodar elas
imagine que Joao mandou o container dele contendo o e-commerce dele, e a Ana mandou o container dela contendo um site de noticias
durante a black friday, houve um pico de acessos no e-commerce do joao, que sugou todos os recursos computacionais do servidor (host)
o servidor travou e, consequentemente, parou de rodar o container da Ana tambem
obs: esse ~storytelling foi roubado daqui
Vamo bota a mao na massa entao.
Primeiramente, vamos instalar o cgroup-tools:
~# apt install cgroup-tools -y
Logar Fontes:
-
Rahul Singh: <video 6min> overlayFS | CVE-2021-3493 | Technical Details
-
School of Devops: <video 10min> Lesson 4: Whats under the hood - Namespaces, Cgroups and OverlayFS
-
Archlinux: <artigo> Overlay filesystem
-
Brian Holt (Frontend Masters, Microsoft): <artigo>Complete intro to Containers
-
CSC-Devops (NC State University): <tutorial>Containers
Diferenças entre VMs e Containers
Tempo estimado de leitura: 3min
Recomendação de materiais
Relembrando FSO
| Conceito | "Definição" |
|---|---|
| Sistema Operacional | Kernel + Apps de Sistema |
| Kernel | coração do S.O., primeiro programa executado quando se inicia um SO; responsavel por gerenciar recursos do computador [uso da cpu, memoria ram, etc] de acordo com as demandas de Apps de Sistema e Apps comuns A interface entre Software e Hardware |
| Apps de Sistema | sistema de arquivos, programas de network, drivers etc; (nao sao os programas "comuns", como navegador, vscode, discord etc) |
Aprofundando um pouco em Máquinas Virtuais
Existem dois tipos de Hypervisors (softwares que lidam com VMs):
| Distinções | Tipo 2 | Tipo 1 |
|---|---|---|
| Conhecido como: | Virtual Machine Monitor (VMM) | Nativo/Bare Metal |
| Softwares: | Qemu, VMware Workstation, Oracle Virtual Box | Xen HVM, KVM*, VMware vSphere |
| Onde roda: | Em cima do sistema operacional que voce estiver utilizando | No Hardware do seu computador (usa a bios e td mais) |
| Na prática: | O mais comum/conhecido: você instala um aplicativo no seu PC, e nele tem uma tela pra você adicionar os SO's que quiser. Então, voce pode bootar em qualquer um desses SO's que estarão disponiveis em janelas de aplicativo diferentes. | No geral, em vez de instalar um sistema operacional, se instala o Hypervisor, e neste você será capaz de instalar varios S.Os (chamados de guests) distintos; A diferença disso p/ um dual-boot, por exemplo, é que multiplos SOs podem ser executados simultaneamente |
Ou seja, no tipo 1, o Hypervisor pode ser considerado um Kernel; no tipo 2, o Hypervisor se aproveita do Kernel utilizado para gerenciar os recursos de suas VMs
Lembrando que cada máquina virtual, naturalmente, terá seu próprio Sistema Operacional e, consequentemente, seu próprio Kernel, também!
Fontes:
-
Pluralsight: <vídeo 5min> Type 1 vs. Type 2 Hypervisors
-
Phoenixnap: <artigo> What is a Hypervisor? Types of Hypervisors 1 & 2
Aprofundando um pouco em Containers
Containers consistem de virtualizações do Sistema Operacional (em vez do Hardware). Têm como caracteristicas o isolamento e gerenciamento de recursos. Isso é possível pela existencia das seguintes funcionalidades do Kernel Linux:
-
Namespaces: responsavel pelo isolamento [processos distintos enxergam recursos (hostnames, ids de usuarios, ids de processos, etc) distintos]
-
Cgroups: responsavel pelo gerenciamento de recursos [limita, prioriza e controla grupos de processos quanto ao uso de CPU, memória, I/O, network, etc]
Ou seja, com apenas 1 Kernel (o do computador que está utilizando agora) consegue-se instanciar inumeros containers (todos se utilizando do seu Kernel), sendo que cada um destes é apenas um processo a mais no seu computador.
Justamente por isso, você não conseguiria rodar um container com imagem Windows num pc Linux: via de regra, o kernel especificado no seu Dockerfile tem de ser compativel com o sistema operacional do seu computador.
*mas é possivel utilizar imagens linux dentro do windows, caso utilize o WSL (Windows Subsystem for Linux)
Fontes:
-
IBM Cloud: <video 8min> Containerization Explained
-
dotCloud: <artigo> PaaS under the hood, episode 1: kernel namespaces
-
McMaster University: <slides> Docker – OS Level Virtualization
-
Wikipedia:
-
Stackoverflow: How is Docker different from a virtual machine?
Resumo
| Virtualização | Comportamento |
|---|---|
| Máquinas Virtuais |   |
| Container Docker |  |
Ou seja, num cenário onde você gostaria de rodar seu app multiplas vezes simultaneamente (por questões de escalabilidade, por exemplo):
| VMs | Containers |
|---|---|
| Necessitaria de 1 máquina virtual para cada instancia; cada máquina virtual necessita, normalmente, de dezenas de GB para armazenar no Host geralmente precisa-se de alguns minutos para bootar | necessita-se de apenas 1 imagem (que pesa lá seus 200mb~1gb) e pode-se instanciar infinitas vezes, de forma quase instantanea |
Conceitos de Docker
Tempo estimado de leitura: 6min
Dockerfile
O Dockerfile provê instruções de como se construir a imagem de um container (usando o comando docker build -t <nome_dessa_img> <caminho_do_dockerfile>). Começa a partir de alguma imagem Base (usando o comando FROM), seguido de quaisquer outras instruçoes necessárias
Então, a gente "compila" esse código, tendo como resultado uma imagem que poderemos interagir com.
principais comandos
| Comando | Descrição | Uso |
|---|---|---|
ARG |
Define uma variavel que o usuário pode passar ao buildar a imagem (usando a flag --build-argessa variável só fica disponivel nas etapas de build da imagem (ou seja, só no dockerfile, mas nao no container) nao use isso pra passar 'segredos' já que os valores podem ser acessados usando |
ˢᶦⁿᵗᵃˣᵉ ↴ ᵉˣᵉᵐᵖˡᵒ ↴ como se usaria: |
ENV |
Define uma variavel de ambiente que será utilizada tanto em build-time como em run-time (ou seja, os containers em execução também possuem essa ENV definida). O usuário pode passar o valor utilizando a flag --env ou -enao use ENV caso so precise do valor em build-time |
ˢᶦⁿᵗᵃˣᵉ ↴ ᵉˣᵉᵐᵖˡᵒ ↴ como se usaria: |
FROM |
especifica a imagem base que será utilizada primeiro busca-se essa imagem localmente, caso nao encontre, busca-se no dockerhub o repositorio mais adequado |
ˢᶦⁿᵗᵃˣᵉ ↴ ᵉˣᵉᵐᵖˡᵒˢ ↴ padrão
usando imagem de outro registry (ECR da AWS)
recebendo plataformas da cli como
ARG |
LABEL |
adiciona metadados a imagem. é feito através de pares de key-value (criados por você mesmo) isso pode ser, então, verificado com o comando docker inspect |
ˢᶦⁿᵗᵃˣᵉ ↴ ᵉˣᵉᵐᵖˡᵒ ↴ |
WORKDIR |
define qual será o diretorio de trabalho em build-time (o caminho relativo de qualquer comando RUN, CMD, ENTRYPOINT, COPY e ADD será esse diretório);caso o diretório não exista, este será criado caso passe um caminho relativo (não-absoluto), este será usado em relação ao ultimo WORKDIR definido |
ˢᶦⁿᵗᵃˣᵉ ↴ ᵉˣᵉᵐᵖˡᵒ ↴ o resultado seria: . |
USER |
configura qual será o usuário (opcionalmente o grupo, também [caso não especifique, será root]) que será utilizado dali em diante (tanto em build-time como run-time)o usuário tem que ser criado por você previamente no dockerfile |
ˢᶦⁿᵗᵃˣᵉ ↴ ᵉˣᵉᵐᵖˡᵒ ↴ |
COPY |
copia arquivos/diretorios do Host (em relação ao contexto da build) para o Container (em relação ao pode-se utilizar wildcards nos caminhos advindos do host:
|
ˢᶦⁿᵗᵃˣᵉ ↴ A versão com ᵉˣᵉᵐᵖˡᵒ ↴ |
ADD |
O mesmo que o
|
ˢᶦⁿᵗᵃˣᵉ ↴ ᵉˣᵉᵐᵖˡᵒ ↴ |
CMD |
Provê algum padrão pro container em execução
|
ˢᶦⁿᵗᵃˣᵉ ↴ ᵉˣᵉᵐᵖˡᵒ ↴ |
ENTRYPOINT |
permite configurar um container pra ser rodado como um executavel |
ˢᶦⁿᵗᵃˣᵉ ↴ ᵉˣᵉᵐᵖˡᵒ ↴ |
BuildKit - Segredos
No Windows/Mac, BuildKit já é utilizado por padrão; no Linux, não. Para saber como ativar, leia aqui
Caso queira, o comando abaixo verifica se o arquivo de configurações personalizadas já existe e, caso nao exista, cria o mesmo já especificando o uso do Buildkit:
$ test -f /etc/docker/daemon.json || (echo '{ "features": { "buildkit": true } }' | sudo tee /etc/docker/daemon.json)
~~ dar exemplo com segredo do Github, JWT ou bCrypt etc
otimizando build
docker layered cache

Only the instructions RUN, COPY, ADD create layers. Other instructions create temporary intermediate images, and do not increase the size of the build.
Docker cacheia as instruções no Dockerfile por camadas. Fazendo um paralelo com a Torre de Hanoi: pense que o Dockerfile é a torre (de cabeça pra baixo); entao, sempre que ouver alteração em alguma linha/camada, todas as peças que estão em cima são descartadas.
Por isso é tão frequente ver a seguinte estrutura em um projeto JS:
| Correto | Incorreto |
|---|---|
|
|
Já que o comando COPY . . copia todos os arquivos, e o código-fonte está em constante alteração, isso significa que toda vez que fosse buildar essa imagem, haver-se-ia de descartar o comando seguinte (npm install), resultando na re-execução desse comando.
comando onbuild
multistage build
dockerignore
volumes
docker pull
registry x repositories
https://stackoverflow.com/a/34004418/11947314
running a container
interactively
background
log files
remove containers
remove images
docker ps
docker swarm
Instalação do Docker
Tempo estimado de leitura: 1min
Docker
O método mais recomendado é indo diretamente pela fonte: Install Docker
Mas, por questões de simplicidade:
$ curl -sSL https://get.docker.com/ | sh
$ exec $SHELL
$ sudo usermod -aG docker $(whoami)
Verifique se consegue rodar normalmente:
$ docker run hello-world
Docker-compose
Novamente, o mais recomendado é ir direto pela fonte: Install Docker Compose
Mas, por simplicidade -> para instalar a versão mais atual do docker-compose, execute o seguinte script:
url="https://github.com/docker/compose/releases/latest"
latest_version=$(curl $url -s -L -I -o /dev/null -w '%{url_effective}' | { read -r redirected_url; echo "${redirected_url##*/}"; })
curl -L https://github.com/docker/compose/releases/download/"$latest_version"/docker-compose-"$(uname -s)"-"$(uname -m)" > /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
Verifique que instalou corretamente:
$ docker-compose -v
docker-compose version 1.29.2, build 5becea4c
Appointment-Octopus
Tempo estimado de leitura: 1min
Esse aplicativo consiste de uma ideia muito simples: agendamento de consultas. Em tese, seria utilizado por um profissional da saúde/personal trainer (por exemplo), onde os pacientes podem visualizar os horarios disponíveis e agendar uma consulta (com o pagamento antecipado).
Resumão Documentação
Tempo estimado de leitura: 3min
Nesse capítulo você terá um resumo sobre a importância de um repositório para guardar informações, digamos, mais 'técnica' sobre o desenvolvimento de um projeto.
Explicação
Independente do quão grande um projeto Open Source pode ser, é sempre importante manter todos os passos documentados, até porque, outras pessoas precisam saber o porquê das coisas.
O porquê escolheu essa arquitetura, como fazer para compilar seu código e como utilizar o trabalho que foi feito até aquele momento. Existem vários modelos de documentos que regem esses 'Artefatos', mas o importante mesmo é saber explicar para os outros como utilizar seu produto, e o README é um bom lugar para colocar algumas dessas informações como uma breve descrição do nome e o que seu produto faz.
Docs Appointment
Acesse aqui o Repositório.
Embora não tenhamos criado todo o aparato de documentação que geralmente aparece, como documento de visões e de arquitetura (dentre outros,como políticas de branch e de commits), listamos aqui alguns artefatos produzidos que nos ajudaram a visualizar melhor o que gostaríamos de produzir.
Para conseguirmos ter aquela ideia visual melhor sobre a nossa aplicação, fizemos alguns casos de uso e um protótipo.
Licença
Como a maioria dos Commits iniciais de um repositório, adicionamos a licença, que é uma espécie de documento contratual que te permite comercializar, editar, distribuir seu software. Embora não vamos entrar em tantos detalhes, é bom saber que existem vários tipos de licença, e com restrições de uso, tanto para utilização como para desenvolvimento, e divergem, então é sempre bom parar um pouco para ler mais sobre algumas, principalmente para saber qual é aquela que melhor se encaixa no contexto do seu produto e/ou organização.
No nosso caso, a escolhida foi MIT License que em resumo é: Uma licença que "permite usar, copiar, modificar, mesclar, publicar, distribuir, sublicenciar e / ou vender", sem qualquer restrição. Então disponibilizamos do jeito que está, qualquer um pode usar, e não tem nenhuma garantia nossa em cima do que foi produzido.
Use Cases
Pode visualizar os casos de uso aqui.
Tanto os casos de uso como o protótipo caminharam juntos na sua estruturação, já que os casos de uso eram para saber tudo o que um usuário poderia fazer e como ele o faria dentro da plataforma, desde coisas simples, mas que foram descritas, como:
- *logar* na aplicação
- escolher uma consulta;
- adicionar um cartão;
- adicionar um método de pagamento;
Enquanto obtínhamos essas descrições, íamos colocando esses elementos em um protótipo - efetuar a compra;
Protótipo
Pode acessar o protótipo aqui.
Paleta de Cores + Tipografia
A parte principal.
Com isso construímos todas as telas de forma consistente.
Via de regra, as telas são compostas de: 60% cor básica + 30% cor primária + 10% cor de acentuação
As cores primárias são a maior identidade visual da sua aplicação, as cores básicas são utilizadas para background e/ou texto (escala de cinzas) e, por fim, a cor de acentuação é utilizada para destacar algo relevante (normalmente alguma ação)
Por fim, as cores de controle são padrões universais (ex: verde = sucesso, vermelho = falha/perigo, etc)
Telas do usuário


DB - Data Base
Pode visualizar as especificações do banco de dados aqui.
Nosso Banco de dados, uma das nossas primeiras tomadas de decisão foi tentar entender como seria o comportamento entre os nossos serviços, sendo assim, quais seriam os dados que de cada um iria guardar e quais dados seriam manipuladaos por cada um.
Depois de esquematizarmos quiais seriam todas as "Entidades", que nada mais são do que estruturas com mais de uma informação importante para se guardar, nosso MER (Modelo Entidade Relacionamento) esquematizamos um modelo lógico e conceitual de como seria o nosso banco.
Caso queiram saber, utilizamos o BrModelo para auxiliar na criação desses modelos, o MER e o diagrama Lógico de bancos.
Esses passos nada mais são que etapas para execução de uma modelagem de um tradicional banco de dados. Logo após essa modelagem levantamos scripts em SQL para criação e população de dados nesse banco, basicamente para saber se a modelagem foi realizada com êxito.
Resumão Backend
Tempo estimado de leitura: 1min
Nesse capítulo você terá um resumo sobre a ideia do backend, estruturado como microsserviços, e vamos explicar também cada microsserviço contido dentro do projeto.
Microsserviços
Diferentemente de uma arquitetura moldada em um software monolítico (uma aplicação onde todos os processos estão acoplados em um único lugar), optamos por uma organização de desenvolvimento estruturada em microsserviços, onde cada pequeno serviço tem sua responsabilidade independente e se comunicam utilizando de APIs que são bem definidas. Dessa forma facilita designar a responsabilidade de cada serviço a pequenas equipes que conseguem se autogerir.
"As arquiteturas de microsserviços facilitam a escalabilidade e agilizam o desenvolvimento de aplicativos, habilitando a inovação e acelerando o tempo de introdução de novos recursos no mercado."
fonte: https://aws.amazon.com/pt/microservices/
Entretanto, não seguimos 100% a risca: utilizamos um unico banco de dados para todos os serviços.
Appointments
https://github.com/appointment-octopus/appointments
É o nosso microsserviço responsável por todo o CRUD (Create, Read, Update e Delete ) das consultas. É possível ver as consultas de um usuário (tanto as que passaram, como as que ainda acontecerão) e, também, listar horários disponíveis para agendar.
Stack: Javascript + Express.js + Sequelize + Jest
Auth
Microsserviço responsável pela autenticação do usuário. Cria usuário, faz login (e gera um token jwt), logout etc.
Stack: Go + mux + Gorm + redigo (cache do usuário)
Resumão Frontend
Tempo estimado de leitura: 1min
Nesse capítulo você terá um resumo sobre a ideia do Frontend, que se encontra como um microsserviço no nosso projeto.
Front
Nosso Frontend no início tinha o objetivo de ser composto por um aplicativo de usuário, e por um de adminitrador.
O de usuário (UserApp), consistia em:
- login;
- navegação;
- escolha do tipo de consulta;
- adicionar métodos de pagamento;
- agendamento da consulta propriamente dito.
Quanto ao de administrador, iria "liberar" dias possíveis juntamente com seus horários para as consultas poderem ser realizadas.
Devido ao escopo que propomos e até onde conseguimos produzir, o único que foi 'planejado e construído', ao menos de forma visual foi o app de Usuário.
UserApp
Microsserviço responsável pela parte visual, logo o nosso Frontend. Como nos propomos a desenvolver uma aplicação mobile utilizamos React Native, como framework, e com o auxílio do StoryBook que é uma ferramenta open source para construção de componentes de interface, e o desenvolvimento de páginas.